
- How a guy with WordPress and a GPT-4 subscription can generate infinite content
- BuzzFeed has started using AI in January to generate content
- Before them, CNET Money has silently started publishing ChatGPT-generated content (full of inaccuracies that nobody bothered to fact-check)
- An AI makes it easy to paraphrase other AIs to not get caught by other AIs
- The publisher of the UK Daily Mirror wants to play the automated content publishing game, too
- The publisher of Sports Illustrated has been way faster than them
- It really doesn’t look bright for mediocre journalists, but they will fight back. Yes. By demanding a subsidy
- And by using AI to make you pay even harder for the AI-generated content that is inspired by your conversations on social media
- LinkedIn launches “collaborative articles” where AI does a tiny bit and you, the user, do the rest (their role in all of this is profiting, in case you are wondering)
- Every publishing platform and channel will be saturated with AI-generated content. It already started
- And it’s so severe that organizations like AP, Nature, Elsevier, and The Committee on Publication Ethics, had to create anti-AI policies
As I wrote in the Free Edition of this Issue, this is the first monthiversary of Synthetic Work. I owe you a special thank you, without jokes, because your support as paying members keeps the project alive.
This week, we talk about the Publishing industry. Wild things are happening under our noses.
Alessandro
What we talk about here is not about what it could be, but about what is happening today.
Every organization adopting AI that is mentioned in this section is recorded in the AI Adoption Tracker.
Let’s start small. In fact, let’s start microscopic. So you have a sense of what a single individual can do with AI these days. Then, we’ll talk about the questionable things that publishing companies have started doing.
I’ll use two tools:
- WordPress, the open source content management system that powers 43% of Internet websites, and has an infinite number of plug-in to expand its capabilities
- Uncanny Automator, one of the most powerful plugins ever created for WordPress.
Uncanny Automator is a bit like IFTTT or Zapier if you have ever tried them. It allows you to create automation workflows triggered by events inside one system (WordPress, an email inbox, a spreadsheet, etc.) and, in reaction to those events, execute specific steps without human intervention in other systems (Twitter, Slack, Salesforce, etc.).
The idea is that this automation layer glues together all 3rd party services out there to build the business processes you need akin to how you build a set with LEGO bricks.
I’ve been a loyal customer of Zapier for years, but Uncanny Automator is so powerful and so flexible, since it works inside my own environment, that I’m thinking about switching to it. It can turn WordPress into my own personal IFTTT/Zapier.
I know what you are thinking: how much did they pay him to say that?
The answer is nothing. This is not an ad. I’m just happy.
So, recently, Uncanny Automator introduced the integration with ChatGPT, through the newly released API to access the gpt-3.5-turbo AI model that underpins ChatGPT.
And this, my dear readers, changes everything.
It allows a single person, to publish a huge amount of content with little to no effort.
All I have to do is is creating a new automation workflow in Uncanny Automator that gets triggered when a new email arrives in a certain Gmail inbox. In the case below, I’m reaching Gmail via Zapier.
Let’s say that the aforementioned email is the new issue of The Morning, a newsletter published by the New York Times with all the important news of the day.
Every time I receive that email in my inbox, my automation workflow is designed contact OpenAI and ask ChatGPT to summarize the content of the newsletter.
I can personalize the prompt as part of the request so, maybe. I can ask ChatGPT to generate a summary written in the style of Woody Allen or Ernest Hemingway.
Once I receive the generated summary, my automation workflow publishes it as a new post in my WordPress blog.
BAAM!
The summary of the summary of the job done by somebody who probably worked really hard to actually write the original story.
I can do this 24/7, with any input. In fact, I don’t even need an input.
I could create something slightly more sophisticated that checks what are the trending terms on Twitter (let’s say elephants), ask ChatGPT to generate a completely made-up article on elephants, publish it on WordPress or anywhere else, and post a tweet about it with the appropriate hashtag.
The (almost free) perpetual garbage generator. Slap ads on it, and you might even have profit.
Now. If an individual can do that, what’s happening in the publishing industry? What’s the impact of AI there?
To understand what’s happening there we need to split the topic in two. Yes, because on one side, publishers have huge ethical and moral issues when people submit AI-generated content, while on the other side, they are totally cool when a GPT model generates content for free for their own profit.
Let’s start with the happy side of the industry.
One of the first to publish AI-generated content is BuzzFeed. They started with Infinity Quizzes. Mia Sato reports for The Verge:
In a memo to staff last month, BuzzFeed CEO Jonah Peretti told staff the company would “lead the future of AI-powered content and maximize the creativity of our writers, producers, and creators and our business.”
The first set of quizzes prompts users to input information like names, favorite foods, or a location, and the tool spits out a personalized block of text generated using artificial intelligence. BuzzFeed says human staff write the quizzes and train the prompts and that it’s “a collaborative effort” between the staffer, the AI system, and the user.
…
BuzzFeed stock jumped in January after the news broke that the company would begin using automated tools.
Of course, it’s a collaborative effort between AI and humans. For now. The number of editors that will be necessary to review this AI-generated content will decrease more and more as more accurate large language models get released. Which is happening, as we said multiple times, once a year for major new models. And it will continue happening once a year unless the AI researchers are forced to pause either because they cannot improve the technology any further with the current machine learning approach, or because they observe a concerning emergent behaviour.
Way before BuzzFeed started publishing its Infinity Quizzes, the popular tech website CNET apparently started using AI to generate some of its articles in November 2022, as discovered by the online marketing and SEO expert Gael Breton:
Looks like @CNET (DR 92 tech site) just did their coming out about using AI content for SEO articles. pic.twitter.com/CR0IkgUUnq
— Gael Breton (@GaelBreton) January 11, 2023
Other web properties owned by the owner of CNET are publishing AI-generated content as Tony Hill, another SEO expert, discovered:
https://t.co/TKEQ2GZnVu, one of the largest finance sites on the web has now started using AI to write some of its content. A big moment in web publishing and #SEO pic.twitter.com/0ew32iwPzn
— Tony Hill (@tonythill) January 10, 2023
and
https://t.co/ZeNHowJmxI pic.twitter.com/oi3vbIJ2bY
— Tony Hill (@tonythill) January 10, 2023
Gael developed a tool that tries to assess the probability that an article has been written by AI, but it’s easy to fool it, just like it’s easy to fool watermarking technologies (we’ll dedicated a special issue of Synthetic Work to that in the future). All you have to do is using a paraphrasing tool like QuillBot.
The AI that paraphrases the AI to not be caught by AI.
Back to CNET and other publishers: once caught, CNET admitted using AI by releasing a totally credible story about the high call to help their overworked staff:
In November, our CNET Money editorial team started trying out the tech to see if there’s a pragmatic use case for an AI assist on basic explainers around financial services topics like What Is Compound Interest?and How to Cash a Check Without a Bank Account. So far we’ve published about 75 such articles.
The goal: to see if the tech can help our busy staff of reporters and editors with their job to cover topics from a 360-degree perspective. Will this AI engine efficiently assist them in using publicly available facts to create the most helpful content so our audience can make better decisions? Will this enable them to create even more deeply researched stories, analyses, features, testing and advice work we’re known for?
I use the term “AI assist” because while the AI engine compiled the story draft or gathered some of the information in the story, every article on CNET – and we publish thousands of new and updated stories each month – is reviewed, fact-checked and edited by an editor with topical expertise before we hit publish.
…
Will we make more changes and try new things as we continue to test, learn and understand the benefits and challenges of AI? Yes.
You bet that they will continue to make money out of this!
There’s only one problem with this: it took just one day for people to find dramatic errors in the AI-generated articles. Which means that no human editor actually has reviewed what the AI has written.
I highly encourage you to review the errors, reported on Futurism by Jon Christian (and perhaps never read CNET again?). He makes the point worth making:
If these are the sorts of blunders that slip through during that period of peak scrutiny, what should we expect when there aren’t so many eyes on the AI’s work? And what about when copycats see that CNET is getting away with the practice and start filling the web with their own AI-generated content, with even fewer scruples?
At this point, you might think that this episode discouraged other publishers. And you’d be wrong.
The UK publisher of The Daily Mirror, called Reach, can’t wait to start, as Arjun Neil Alim reports for Financial Times:
Reach chief executive Jim Mullen told the Financial Times the company had set up a working group to examine how the tool might be used to assist human reporters compiling coverage of topics such as local weather and traffic.
“We’ve tasked a working group, across our tech and editorial teams, to explore the potential and limitations of machine-learning such as ChatGPT”, he said. “We can see potential to use it in the future to support our journalists for more routine stories like local traffic and weather or to find creative uses for it, outside of our traditional content areas.”
…
Reach publishes more than 130 national and regional titles including the Daily Record and the Manchester Evening News. Last month the company warned that its annual profit would be lower than expected after it was hit by cost inflation and lower advertising rates, especially in print. It also said it would cut about 200 jobs in its editorial and commercial teams out of a total headcount of 4,500.
…
Chris Morley, the National Union of Journalists’ co-ordinator for Reach, expressed some concern and said that he would “be seeking meetings with the company”.“I am concerned that the company hasn’t spoken to us in the first place as there’s a potential impact on jobs,” he said. “We’re going through 200 job losses in the group, it’s been a painful process”.
Francesco Marconi, co-founder of computational journalism company AppliedXL, who used to work on automation and AI at the Associated Press, said the application of ChatGPT in journalism would be in “supporting functions”.
Speaking of which, did you know that the prestigious Associated Press is using AI for news summary generation and other tasks?
Our objective in production is to streamline workflows to enable our journalists to concentrate on higher-order work. This ranges from the automatic transcription of video to experimenting with the automatic-generation of video shot-lists and story summaries. We also currently automate stories in both sports and corporate earnings.
And, of course, it’s not over.
Alexandra Bruell, reports for the Wall Street Journal:
The publisher of Sports Illustrated and other outlets is using artificial intelligence to help produce articles and pitch journalists potential topics to follow, the latest example of a media company investing in the emerging technology.
The Arena Group Holdings, whose publications include TheStreet, Men’s Journal and Dealbreaker, said it is working with AI startups Jasper and Nota as part of an effort to generate stories that pull information from its own library of content. The company is also using technology from OpenAI, the creator of ChatGPT, a chatbot that has generated considerable buzz among consumers and businesses due to its humanlike, content-producing capabilities.
Some articles in Men’s Journal are already AI-generated, the company said, such as “Proven Tips to Help You Run Your Fastest Mile Yet,” and “The Best Ways for Men Over 40 to Maintain Muscle.” The articles were created based on information from 17 years of archived stories from Men’s Fitness, a brand that exists under Men’s Journal.
…
“It’s not going to replace the art of creating content,” said Ross Levinsohn, Arena Group’s chairman and chief executive. “It’s giving the content creators, whether they’re writers or social creators, real efficiency and real access to the archives we have.”
The last comment is incredibly important.
As I hinted at the beginning of this Issue, a large language model can generate content starting from any input.
Publishing houses don’t need journalists to produce that input. They have 4.9 billion input sources that tell them exactly where the attention is: us, talking to each other on social media.
If you have read any of the top newspapers in the last five years, you must have noticed that a growing number of news are supported or revolve around a tweet. Which is just a conversation among a group of people, taking place in a public forum where everybody can hear.
If journalism is the art of narrating the story of us, nothing could be more direct than eavesdrop on what we are saying. The more our conversations are digital and public, the easier is for AI to summarize and embellish them in a lovely article.
And where AI can’t access those conversations, it can easily invent them, inspired by all the conversations it has been trained on.
In all of this, and this is the point, the journalist becomes an unnecessary intermediary between the source of conversations, us, and the publishing company.
Maybe not every journalist. Certainly not the investigative journalists that work one year on a story that has a wide political, economic, and social impact. But newspapers publish very few articles like that per year. And very few journalists are capable of writing those articles.
What will happen to the others?
Well, while they are freaking out, their publishers are finding an additional way to make money out of this situation.
Keach Hagey, Alexandra Bruell, Tom Dotan and Miles Kruppa all reporting for the Wall Street Journal:
In recent weeks, publishing executives have begun examining the extent to which their content has been used to “train” AI tools such as ChatGPT, how they should be compensated and what their legal options are, according to people familiar with meetings organized by the News Media Alliance, a publishing trade group.
…
Reddit has had talks with Microsoft about the use of its content in AI training, people familiar with the discussions said. A Reddit spokesman declined to comment.Robert Thomson, chief executive of The Wall Street Journal parent News Corp, said at a recent investor conference that he has “started discussions with a certain party who shall remain nameless.”
…
Google already has struck deals to pay some publishers, including News Corp, for using their content in a product called Google News Showcase, which has yet to launch in the U.S.
…
Legislation that would let U.S. publishers negotiate collectively, without running afoul of antitrust regulations, circulated in the last session of Congress and is expected to be reintroduced soon, according to people familiar with the situation. That legislation is intended to cover commercial arrangements including for AI tools, one of the people said.
And now, to add insult to injury, you should expect to see more and more AI used by these publishing companies to protect their newspapers with smarter and smarter paywalls.
A great example is offered by The New York Times, described in a long, technical but fascinating article by Rohit Supekar. I quote only a bit of it, but you should really read it:
The Dynamic Meter model must play a dual role. It should support our mission to help people understand the world and our business goal of acquiring subscriptions. This is done by optimizing for two metrics simultaneously: the engagement that registered users have with Times content and the number of subscriptions the paywall generates in a given time frame. These two metrics have an inherent trade-off since serving more paywalls naturally leads to more subscriptions but at the cost of article readership.
…
The goal of the model is to prescribe meter limits from a limited set of options available. Thus, the model must take an action that will affect a user’s behavior and influence the outcome, such as their subscription propensity and engagement with Times content. In contrast to a predictive machine learning model, the ground truth for prescriptive problems is rarely known. That is, say a user was prescribed meter limit a, we do not know what would have happened to this user if they were prescribed a different meter limit b during the same time frame. This problem is sometimes called the “fundamental problem of causal inference” or more simply the “missing data problem.”
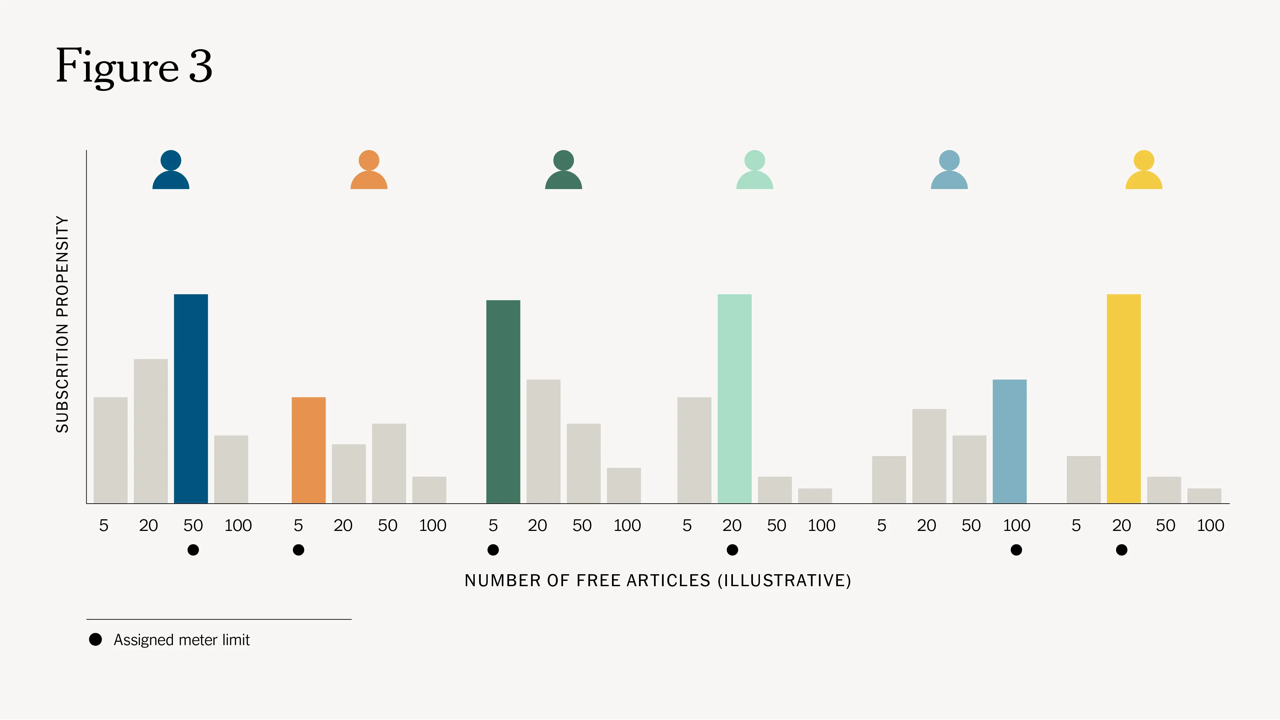
Not sure about you, but I find it cosmic that humans have to pay to go through an AI that is protecting content generated by another AI which, in turn, has taken inspiration from humans.
While you reflect on the idea of karma, I’d like to switch gears a little.
Naturally, flooding a communication channel with AI-generated content is not a game that only publishing companies want to play. Are you kidding me? It sounds too much fun.
Social media networks want in, and LinkedIn is the first (to admit it?) on the block.
Mitchell Clark, writing for The Verge, offers details:
LinkedIn has introduced a feature called collaborative articles, which uses “AI-powered conversation starters” to start discussions between “experts” that use the platform. In an announcement post on Friday, the company says it will “match each article with relevant member experts” based on its skills graph, and invite them to add context, extra information, and advice to the stories.
The company thinks the system will make it easier for people to contribute their perspectives because “starting a conversation is harder than joining one.”
…
According to LinkedIn spokesperson Suzi Owens, “the bodies of the articles are powered by AI,” based on prompts “created by and constantly refined by” the company’s editorial team.The company has already been using the tech to pump out almost 40 articles in the past two days
I’m not 100% sure, but I think that, earlier this week, LinkedIn tried to push one of these articles to me. Here’s what I saw:
The article first appears at the top of your feed as a banner:

Then, if you click on it, you find the skeleton of an article with a series of placeholders:

For each placeholder, you can add your “insight” to the text that the AI has already generated:
What could possibly go wrong?
LinkedIn is already the kingdom of spammers, and this seems like the perfect way to pitch unwanted products to readers.
More importantly, this is a variant of what we discussed above: the end users become the producers of the content they are consuming and from which only publishers (in this case, social media networks) profit.
OK. What else could be generated to flood the publishing platforms?
Books. Novels. Comics. And other things that we don’t name here because we are a respectable publications.
Wink wink.
To understand what will happen on those publishing platforms, we can take a look at what’s happening already today when the content is self-published.
Let’s start with books. To help us, there is Greg Bensinger, writing for Reuters:
Using the AI software, which can generate blocks of text from simple prompts, Schickler created a 30-page illustrated children’s e-book in a matter of hours, offering it for sale in January through Amazon.com Inc’s self-publishing unit.
…
“The Wise Little Squirrel: A Tale of Saving and Investing,” available in the Amazon Kindle store for $2.99 – or $9.99 for a printed version – has netted Schickler less than $100, he said. While that may not sound like much, it is enough to inspire him to compose other books using the software.
…
There were over 200 e-books in Amazon’s Kindle store as of mid-February listing ChatGPT as an author or co-author, including “How to Write and Create Content Using ChatGPT,” “The Power of Homework” and poetry collection “Echoes of the Universe.” And the number is rising daily. There is even a new sub-genre on Amazon: Books about using ChatGPT, written entirely by ChatGPT.But due to the nature of ChatGPT and many authors’ failure to disclose they have used it, it is nearly impossible to get a full accounting of how many e-books may be written by AI.
…
On YouTube, TikTok and Reddit hundreds of tutorials have spring up, demonstrating how to make a book in just a few hours. Subjects include get-rich-quick schemes, dieting advice, software coding tips and recipes.
…
One author, who goes by Frank White, showed in a YouTube video how in less than a day he created a 119-page novella called “Galactic Pimp: Vol. 1” about alien factions in a far-off galaxy warring over a human-staffed brothel. The book can be had for just $1 on Amazon’s Kindle e-book store. In the video, White says anyone with the wherewithal and time could create 300 such books a year, all using AI.
In a matter of hours. Remember how we started this Splendid Edition: with automation. Hours can quickly become minutes, which can quickly become seconds. You just need to know how to do it.
The publisher, Amazon in this case, of course doesn’t give a crap if the book’s content is generated by AI or written by a human being. Or if it’s automated. Because as long as it’s sold, they make a profit.
Both for the speculator and the publishing company, the strategy here is focusing on quantity, not quality. It doesn’t matter if each books only makes $1 in profit.
But if you flood the publishing platform, you drown the human authors that can’t or refuse to write by using AI plus automation. The work of those authors disappears in the noise, and that’s how, all of a sudden, the profession may not viable anymore.
This is a recurring theme on Synthetic Work: if your competitors are using AI to be faster and more prolific than you, can you really afford to not do the same?
Not only the authors are in trouble, but the curators, too.
In the Free Edition of Synthetic Work Issue #3 (For Dummies: How to steal your coworkers’ promotion with AI), we saw how the editor of one of the best science fiction magazines in America has raised a warning about the exponential growth of AI-generated submissions and how they make very hard to do his job.
In that Issue, I suggested that no (human) editor/curator will be able to cope and articulate what might happen next: no need for curation anymore.
We are seeing more of these warning signals elsewhere, as Mia Sato, writing for The Verge, shows:
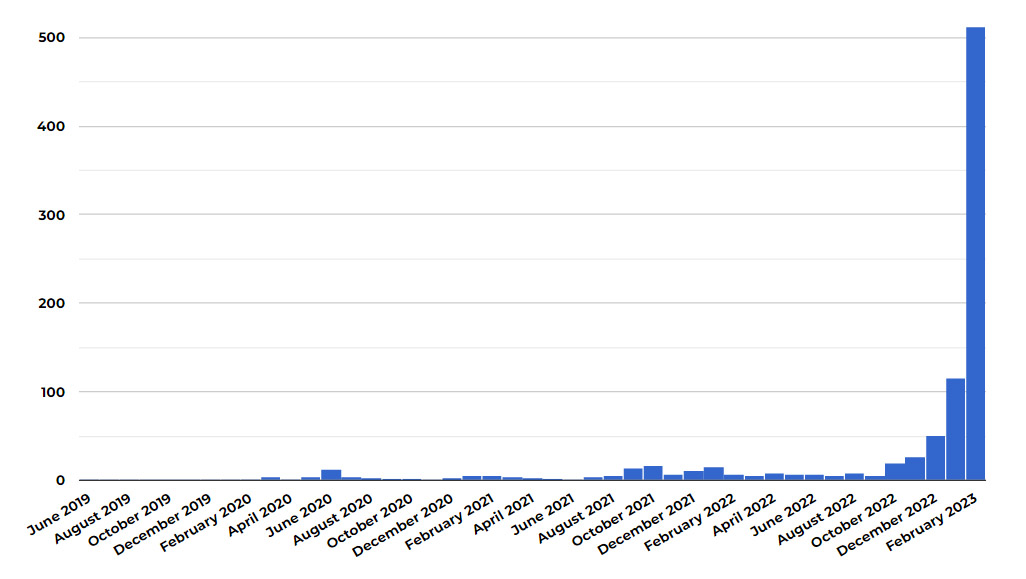
A short story titled “The Last Hope” first hit Sheila Williams’ desk in early January. Williams, the editor of Asimov’s Science Fiction magazine, reviewed the story and passed on it.
At first, she didn’t think much of it; she reads and responds to writers daily as part of her job, receiving anywhere from 700 to 750 stories a month. But when another story, also titled “The Last Hope,” came in a couple weeks later by a writer with a different name, Williams became suspicious. By the time yet another “The Last Hope” came a few days later, Williams knew immediately she had a problem on her hands.
“That’s like the tip of the iceberg,” Williams says.
Since that first submission, Williams has received more than 20 short stories all titled “The Last Hope,” each coming from different author names and email addresses. Williams believes they were all generated using artificial intelligence tools, along with hundreds of other similar submissions that have been overwhelming small publishers in recent months.
Asimov’s received around 900 stories for consideration in January and is on track to get 1,000 this month. Williams says nearly all of the increase can be attributed to pieces that appear to be AI-generated, and she’s read so many that she can now often tell from the first few words whether something might not be written by a human.
…
Flash Fiction Online accepts a range of genres, including horror and literary fiction. On February 14th, the outlet appended a notice to its submission form: “We are committed to publishing stories written and edited by humans. We reserve the right to reject any submission that we suspect to be primarily generated or created by language modeling software, ChatGPT, chat bots, or any other AI apps, bots, or software.”
…
Of the more than 1,000 works FFO has received this year, Yeatts estimates that around 5 percent were likely AI-generated.
As you can see, differently from publishing companies, individuals are not particularly subtle in their use of AI, and this is akin to the next generation spam.
If you could only pollute email inboxes before, now you can pollute absolutely everything.
These stories lead us to the other side of all of this. The one I mentioned at the beginning of this Issue.
This is the side where publishing houses have huge ethical and moral issues in accepting AI-generated content (as long as they can’t profit from it!).
So, who’s on this side?
Last year, Nature reported that some scientists were already using chatbots as research assistants — to help organize their thinking, generate feedback on their work, assist with writing code and summarize research literature
…
The big worry in the research community is that students and scientists could deceitfully pass off LLM-written text as their own, or use LLMs in a simplistic fashion (such as to conduct an incomplete literature review) and produce work that is unreliable. Several preprints and published articles have already credited ChatGPT with formal authorship.
…
That’s why it is high time researchers and publishers laid down ground rules about using LLMs ethically. Nature, along with all Springer Nature journals, has formulated the following two principles, which have been added to our existing guide to authors (see go.nature.com/3j1jxsw). As Nature’s news team has reported, other scientific publishers are likely to adopt a similar stance.First, no LLM tool will be accepted as a credited author on a research paper. That is because any attribution of authorship carries with it accountability for the work, and AI tools cannot take such responsibility.
Second, researchers using LLM tools should document this use in the methods or acknowledgements sections. If a paper does not include these sections, the introduction or another appropriate section can be used to document the use of the LLM.
Save this Issue, because one day we’ll come back to it and you’ll see how money (or lack thereof, due to competition) can change perspective dramatically.
Who else is offended?
The giant publishing company Elsevier is kinda offended, but not too much:
Where authors use generative AI and AI-assisted technologies in the writing process, these technologies should only be used to improve readability and language of the work. Applying the technology should be done with human oversight and control and authors should carefully review and edit the result, because AI can generate authoritative-sounding output that can be incorrect, incomplete or biased. The authors are ultimately responsible and accountable for the contents of the work.
Authors should disclose in their manuscript the use of AI and AI-assisted technologies and a statement will appear in the published work. Declaring the use of these technologies supports transparency and trust between authors, readers, reviewers, editors and contributors and facilitates compliance with the terms of use of the relevant tool or technology.
Authors should not list AI and AI-assisted technologies as an author or co-author, nor cite AI as an author. Authorship implies responsibilities and tasks that can only be attributed to and performed by humans.
About this new policy, Elsevier is already saying that will monitor this development and will adjust or refine this policy when appropriate.
Another one to save for later. Anybody else?
The Committee on Publication Ethics is offended, but only on a legal technicality:
COPE joins organisations, such as WAME and the JAMA Network among others, to state that AI tools cannot be listed as an author of a paper.
AI tools cannot meet the requirements for authorship as they cannot take responsibility for the submitted work. As non-legal entities, they cannot assert the presence or absence of conflicts of interest nor manage copyright and license agreements.
Authors who use AI tools in the writing of a manuscript, production of images or graphical elements of the paper, or in the collection and analysis of data, must be transparent in disclosing in the Materials and Methods (or similar section) of the paper how the AI tool was used and which tool was used. Authors are fully responsible for the content of their manuscript, even those parts produced by an AI tool, and are thus liable for any breach of publication ethics.
To close, in case this is not clear enough:
We just scratched the surface, but it’s enough to become doubtful about how much published content will be generated by human authors (journalists, writers, etc.) in the future.
And remember that GPT-4 has just arrived. And GPT-5 is already in training. And there are another dozen AI models about to be released.
The future is going to be bright for media projects like Synthetic Work.
The future is going to be bright for media projects like Synthetic Work.
The future is going to be bright for media projects like Synthetic Work.
Yes.