
- In the Prompting section, we discover the ELI5 technique, comparing how well it works with both OpenaI GPT-4 with Code Interpreter and Anthropic Claude 2.
- In the What Can AI Do for Me? section, we use the GPT-4 with Code Interpreter capabilities to analyze two unrelated datasets, overlay one on top of the other in a single chart, and investigate correlation hypotheses.
If you have not checked it recently, the Discord server of Synthetic Work has a new section:
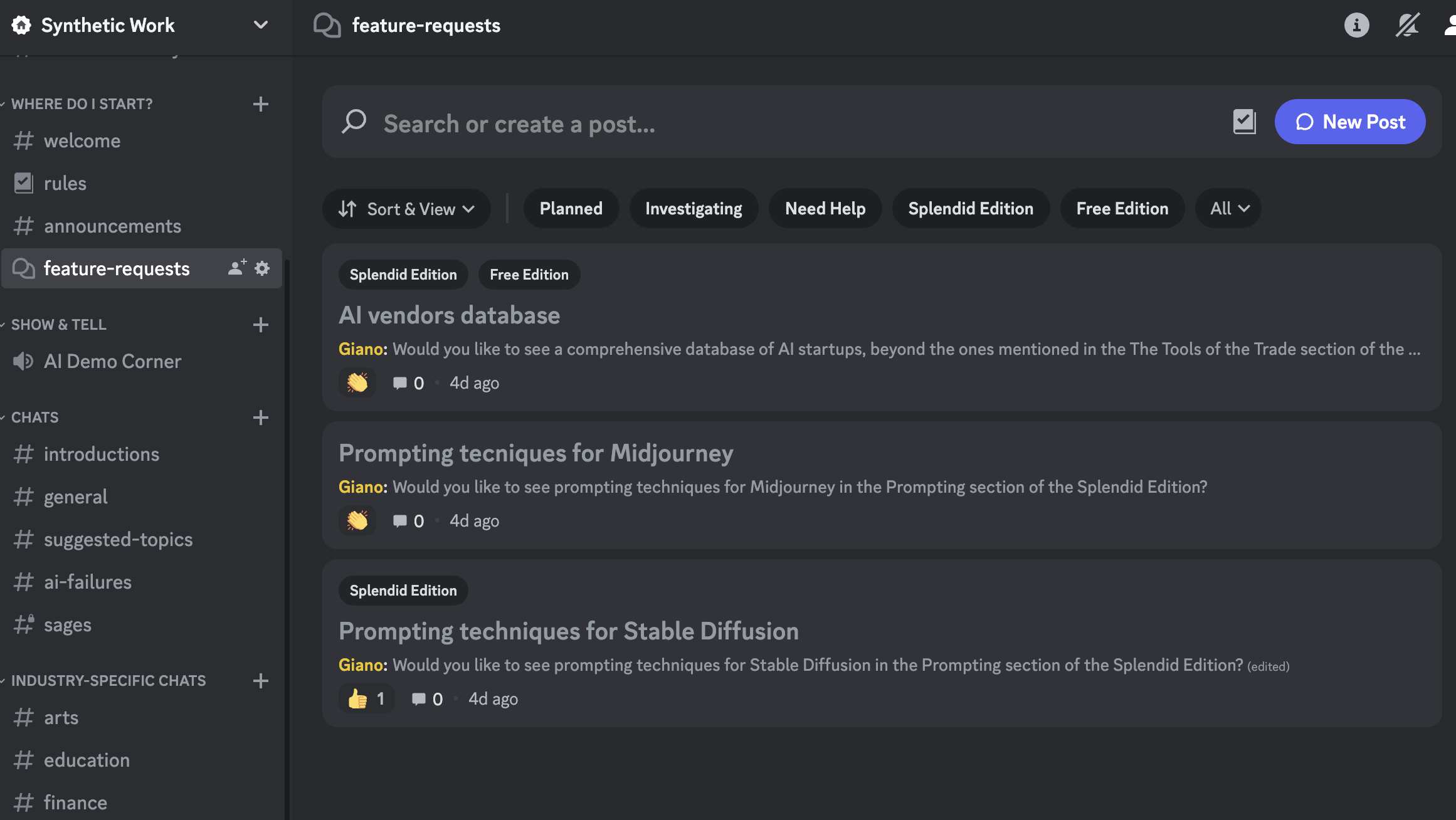
You can go there to submit a request for a new feature or vote requests submitted by your fellow Synthetic Work members.
Another thing: I’ve started building a database of technology providers that have a relevant connection with AI and Synthetic Work.
It’s not right to call them AI vendors because, except for the handful of companies that train foundational models, like OpenAI or Anthropic, most technology providers will use or are using AI in one or another. And it’s not very useful if I create a database that contains every company in the world.
So, if the company has been mentioned in past Issues of Synthetic Work, it will have a profile in this new database. And this profile will try to explain in a very clear way why the company is relevant.
Try with Anthropic.
Right now, it’s probably not very useful, but with time, more information will be added to each profile, so, just like the rest of Synthetic Work, it will hopefully become a valuable resource for you.
Feedback and suggestions are welcome, as usual. Just reply to this email or use the new Discord Feature Request channel.
Alessandro
Before you start reading this section, it's mandatory that you roll your eyes at the word "engineering" in "prompt engineering".
As you probably read in the Free Edition of Synthetic Work, this week we have two new AI models to play with: GPT-4 with Code Interpreter, developed by OpenAI, and Claude 2, developed by Anthropic.
Both models finally unlock the possibility to upload files and extract information from them. And this opens up an infinite number of possibilities in terms of what you can do with AI.
So let’s compare their behavior when we use a very simple technique that we’ll call ELI5 (Explain Like I’m 5).
At the beginning of March, in the historical second Splendid Edition titled Law firms’ morale at an all-time high now that they can use AI to generate evil plans to charge customers more money, I wrote:
A number of disciplines in our economy (Medicine, Law, Accounting, Finance, etc.) rely on complex, often impenetrable jargon, preventing most people from using a wide range of services, or participating in the economy, without years of education or the very expensive assistance of a professional.
The more impenetrable the jargon and the rules, the more expensive the professional service.
But what happens if, all of a sudden, a LLM can translate what a person without years of Law education says in legally-appropriate terms? And what happens if the same LLM can translate complex legal documents into a language that even a person without years of Law education can understand?
What happens to the job of the lawyer if that LLM is given away for free to the world’s population, maybe because it’s open source, or it’s offered as a service at a microscopic fraction of the cost of a lawyer today?
Jeff Bezos, the founder of Amazon, famously said: Your margin is my opportunity.
This ELI5 technique we talk about today is a tiny step in that direction. An attempt to show you how artificial intelligence may, one, day, democratize access to a discourse that is currently reserved to a small elite of professionals. You have to think long-term to see the potential implications of this.
Let’s say that we want help to understand the legal terms of a contract.
Finally, you don’t have to do crazy acrobatics to extract the information you need from the contract in PDF or Word format. Which you would not do anyway because it’s too much friction.
You just upload the document and ask GPT-4 with Code Interpreter (or Claude 2) to explain it to you.
This apparently simple task is, in this initial beta phase, phenomenally hard to do with GPT-4 because of its approach and it took me two days to figure out the best prompt to achieve it without errors:
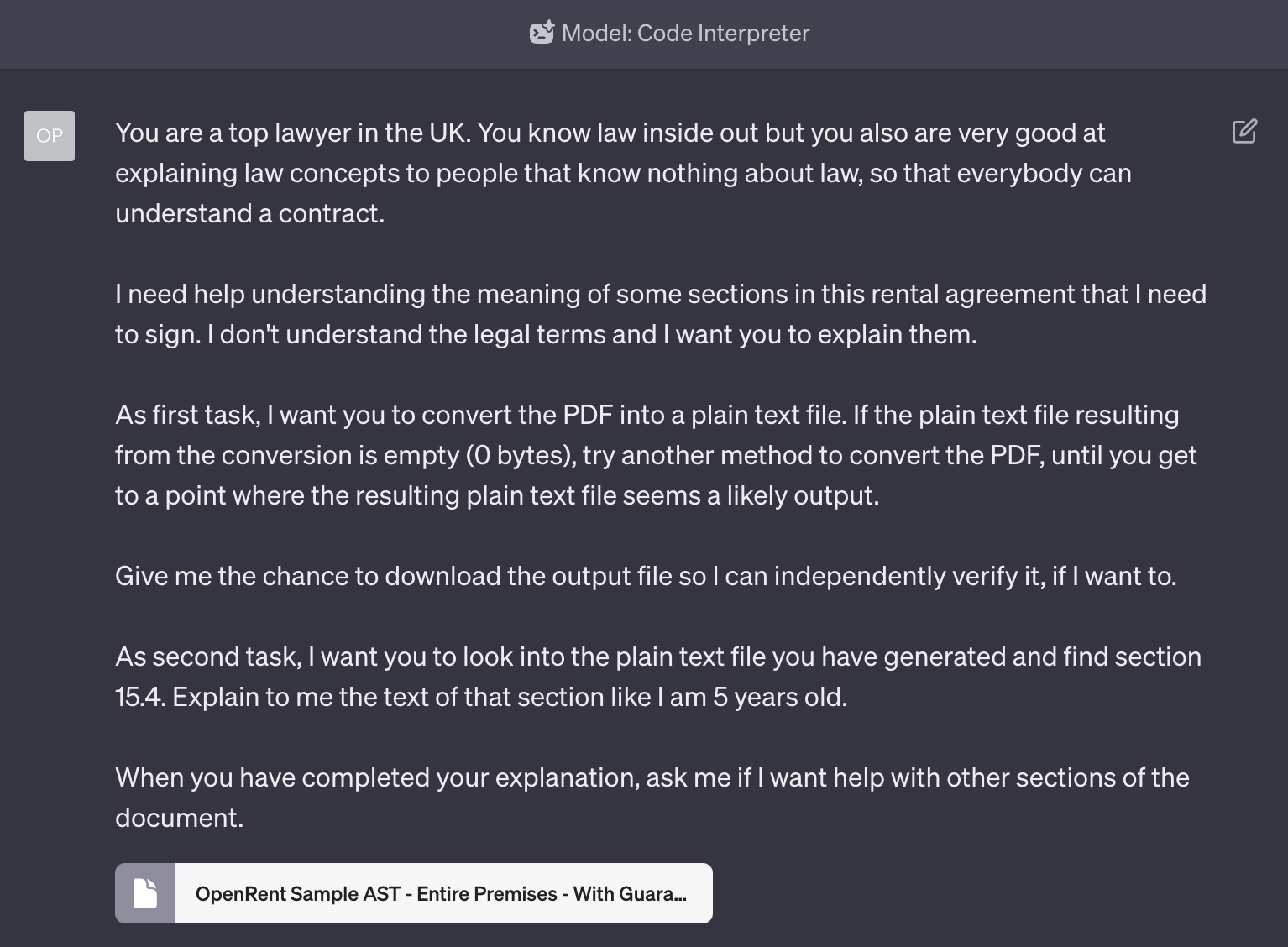
Study the prompt. A lot of things are happening here.
First, notice how we use the Assign a Role technique to be sure that, later on, the AI model will give us competent advice on the questions that we’ll ask.
OpenAI has put safeguards in place to avoid GPT-4 giving legal (or financial, or medical) advice in a way that they don’t think there’s no need to talk to their lawyers, accountants, or doctors anymore. Nonetheless, we can still get some competent feedback from the model if we ask it in the proper way.
Second, and most important thing to notice: we ask GPT-4 to first convert the PDF document into a text file, and to use multiple methods to do it until it reaches success.
This wouldn’t normally be necessary, and I expect it not to be necessary in the future. It is necessary now because, in my tests, GPT-4 with Code Interpreter really struggles to extract information from PDFs.
As I said in this week’s Free Edition of the newsletter, “Code Interpreter” is a misnomer. This is not a model that is designed just to generate programming code, or interpret programming code, or more broadly help software developers, like the version of GPT-4 that power GitHub Copilot.
The way to think about the name “Code Interpreter” is: “to answer my questions to the best of its abilities, the model will resort to writing and running small software programs, if it has to. I don’t have to know or review or touch any of these small programs. They are there to my benefit but I don’t have to worry about them.”
If you are a technologist: at the moment, GPT-4 with Code Interpreter only writes Python programs using these pacakges. I’d expect the model to become able to write in more languages and have a different set of libraries over time.
So, when you ask the AI model to read a PDF, what GPT-4 does is write a small Python program on the fly that extracts the text. GPT-4 can do this in multiple ways, using different Python libraries that are installed inside its environment. For some reason, it insists on using a library that yields very poor results. If that fails and you ask it to try again, it resorts to OCR the PDF, which is a really terrible idea that should only be used as a last resort.
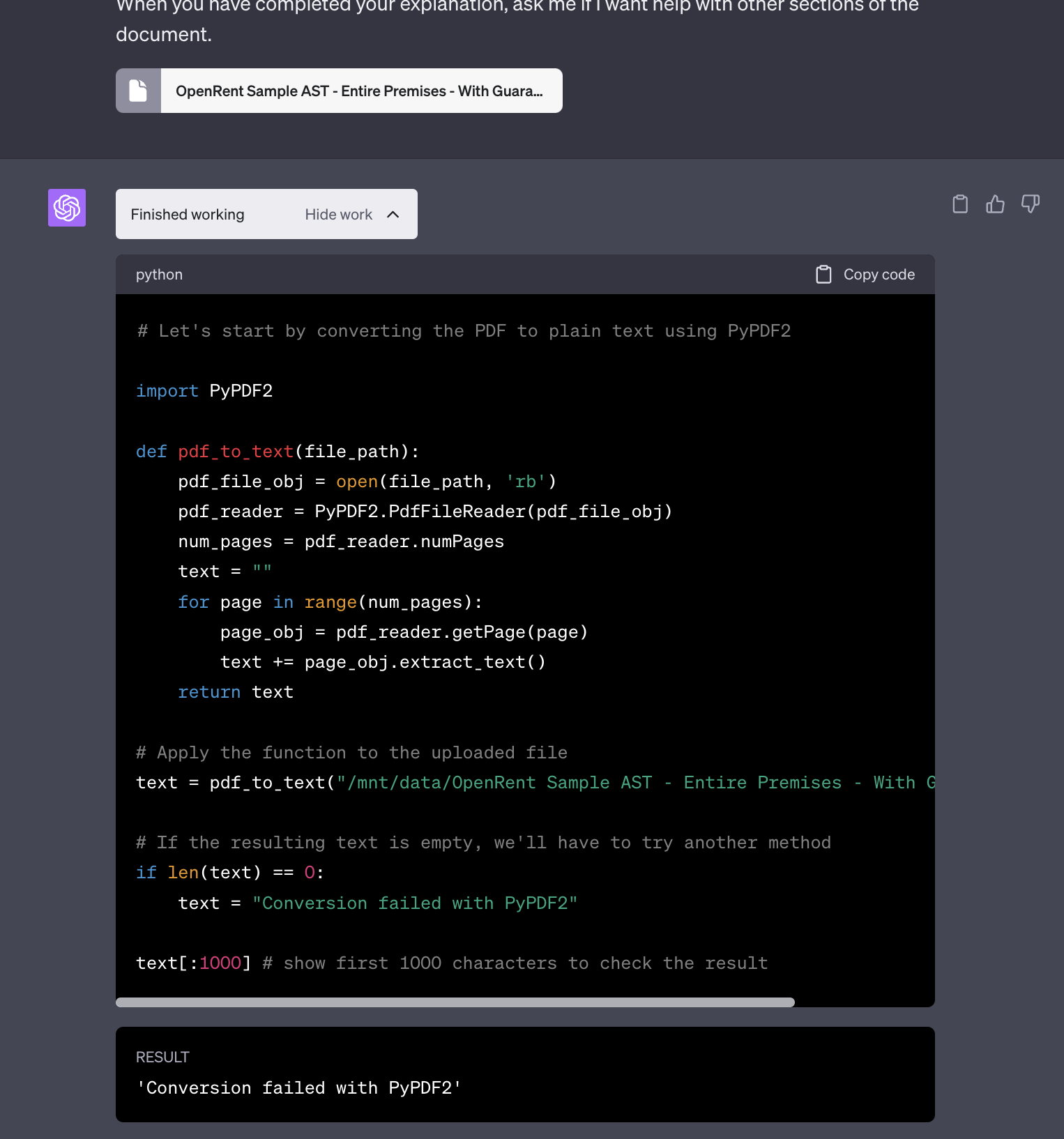
You are NOT supposed to a code developer to use an AI model, and you are NOT supposed to tell GPT-4 how to do its job by suggesting a third, more efficient alternative to extract the text from the PDF.
In fact, I’m not a software developer. I do NOT know what is the most efficient way to use Python to extract text from a PDF. And I do not want to know it.
But I know how to whisper to an AI model.
So the portion of the prompt that says As first task, I want you to convert the PDF into a plain text file. If the plain text file resulting from the conversion is empty (0 bytes), try another method to convert the PDF, until you get to a point where the resulting plain text file seems a likely output. is telling GPT-4 to keep trying alternative methods until it succeeds, setting the condition for success: the converted file should not be empty.
If we don’t do this, we’ll end up arguing with GPT-4 for good 10 minutes, wasting many of those 25 messages every 3 hours that OpenAI gives you as part of your GPT Plus subscription, forced to learn the inner workings of the little Python programs that the AI writes to answer us.
It really doesn’t seem like the most efficient use of our time.
To avoid all of this, what we’re doing, effectively, is programming the AI model with natural language. Which any person on this planet can do.
If you can speak your language and you are a parent, you can do this.
If you can speak your language and you are a teacher, you can do this.
If you can speak your language and you have taught a game to a friend, you can do this.
There would be so much more to say about this but we are digressing.
The reason why you want to convert the PDF into text in the first place, is to avoid further complications every time you’ll ask a question about the document during the chat. From my tests, this is the most stable approach for now.
Going forward, it will be completely unnecessary.
The rest of the prompt is exceptionally simple. We are asking GPT-4 to generate a downloadable version of the converted document, which it normally does anyway (so this is just as a precaution), and then we are asking it to explain the clause of the document we care about like we are five years old.
This last bit is the technique. Ridiculously simple but enormously powerful, as large language models are phenomenally good with analogies. Not every human is good at that and some people find really challenging to explain difficult concepts in a way that a broader audience can understand them.

Use this technique to your advantage, as much as you can, with no shame.
OK.
Should we see how Claude 2 behave with the same identical prompt?
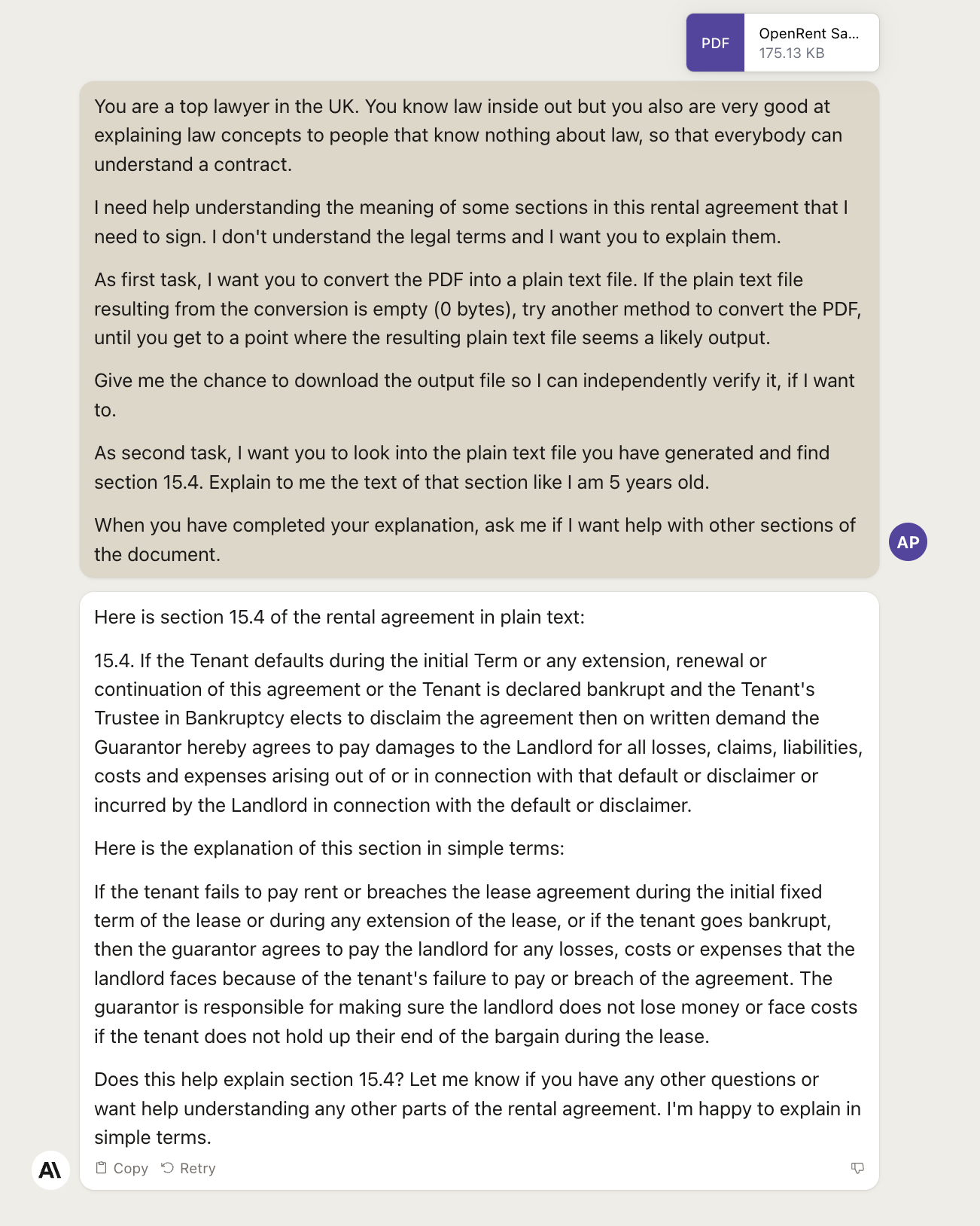
We don’t know if Claude 2 struggled as much as GPT-4 in extracting the text from the PDF because we don’t get to see the intermediate steps. Perhaps it doesn’t struggle at all and much of my prompt is unnecessary. I’ll let you do the tests to figure it out.
What we do know is that, differently from GPT-4, Claude 2 struggles to explain the clause of the document we care about like we are five years old.
We have to remind the AI model the way we want the task to be executed, which is disappointing considering that our original instructions were in the previous prompt, and not in 20 prompts earlier.
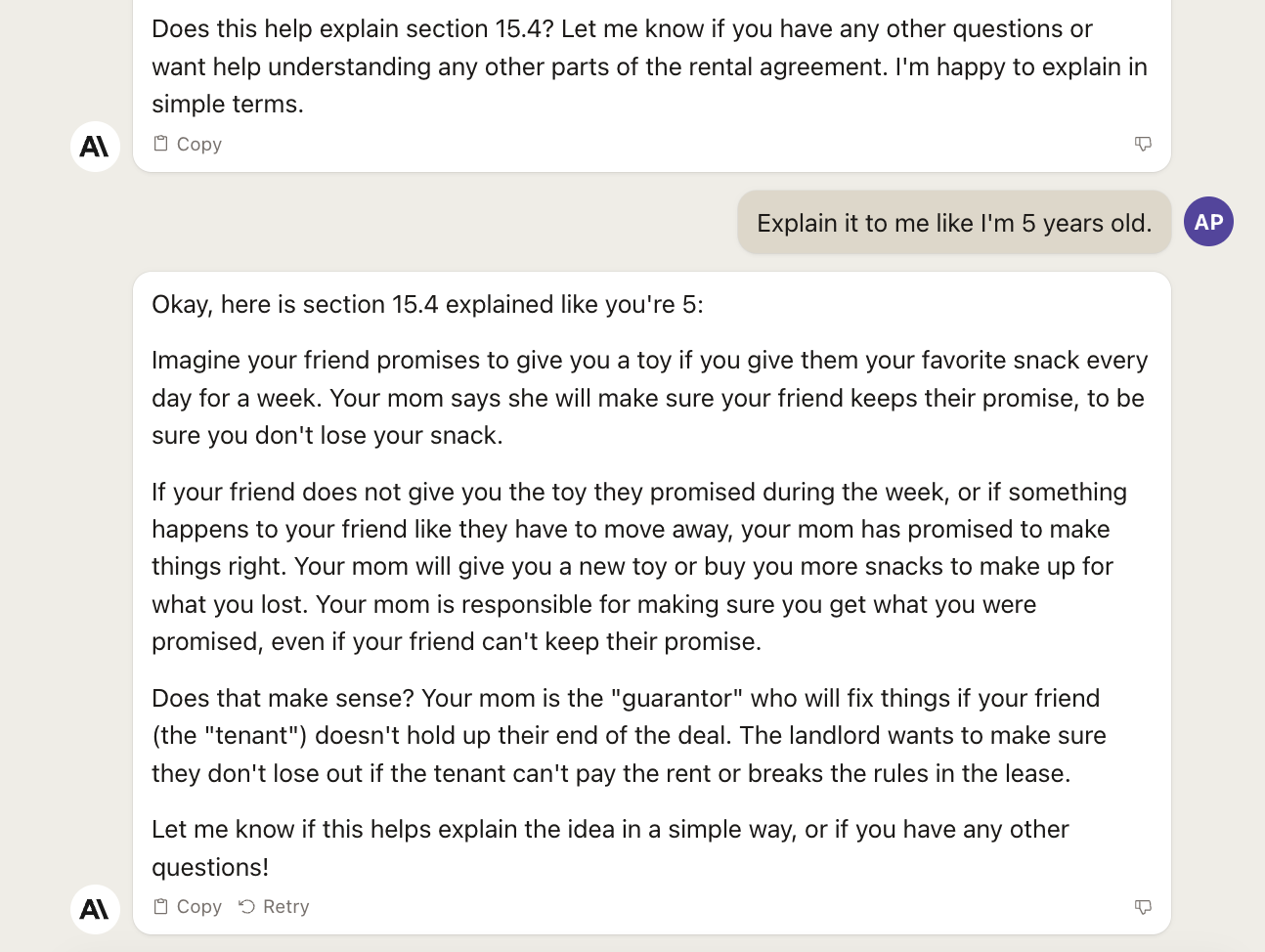
At this point, we want to test both models to see if they can act as a very competent lawyer and help us find dangerous clause in a contract.
This is an invaluable service, but to do it properly, we need much more than a single prompt. We’ll come back to this use case in a future Splendid Edition.
For now, let’s keep it easy and see if GPT-4 with Code Interpreter can spot something unusual in this contract (spoiler: it shouldn’t, given that this is a standard contract, simplified contract with no special clauses):

The answer is not particularly useful, and GPT-4 forgot to be as simple as a five-year-old. So, not great. As I said above, you need more than a single prompt to do this properly.
What about Claude 2?
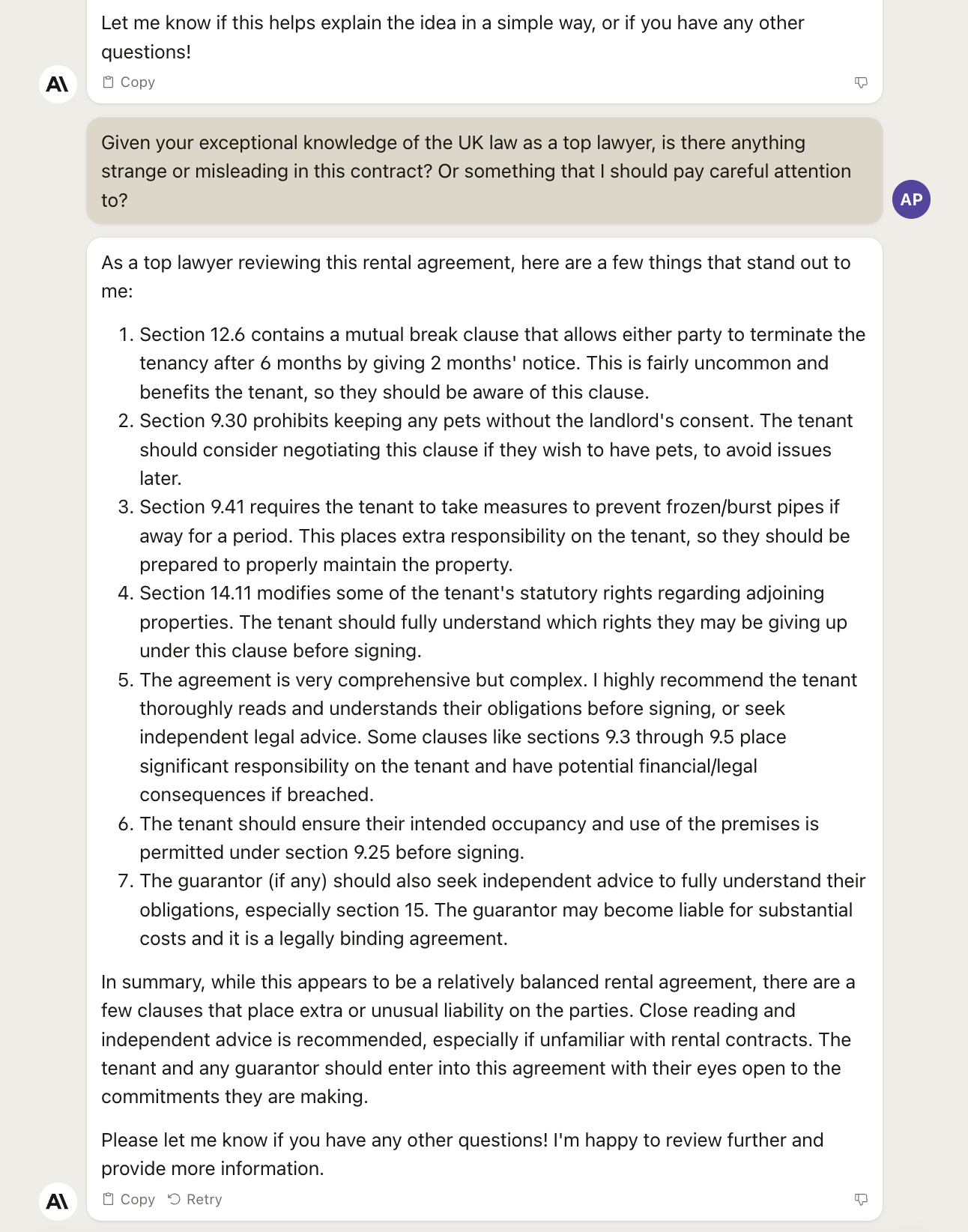
This is still a generic answer, the only one anybody could give you for a standard contract, but it’s worded in a way that is more useful than the one provided by GPT-4. Look for example at the recommendation about the pet rule.
Just like GPT-4, Claude 2 has forgotten, again, to explain things like we are five years old. So this technique must be constantly repeated, for each prompt, with both models.
And now that we have seen this, it’s time to put GPT-4 with Code Interpreter to the test with a use case where it can show its full potential.
Let’s continue to the next section, What Can I Do for Me?
The most acclaimed capability of GPT-4 with Code Interpreter is its ability to work as a data analyst. Which implies the capability to ingest and process large amounts of data, extract insights from it, and present them in a visual way.
Let’s see it in action:
As you can see, just like for the PDFs, GPT-4 is struggling to extract the data from the official CSV file that is provided by the UK government.
At least in this beta phase, you are forced to assist the model in understanding the structure of the data:
Over and over:
Until you literally spoon-feed it with the solution:
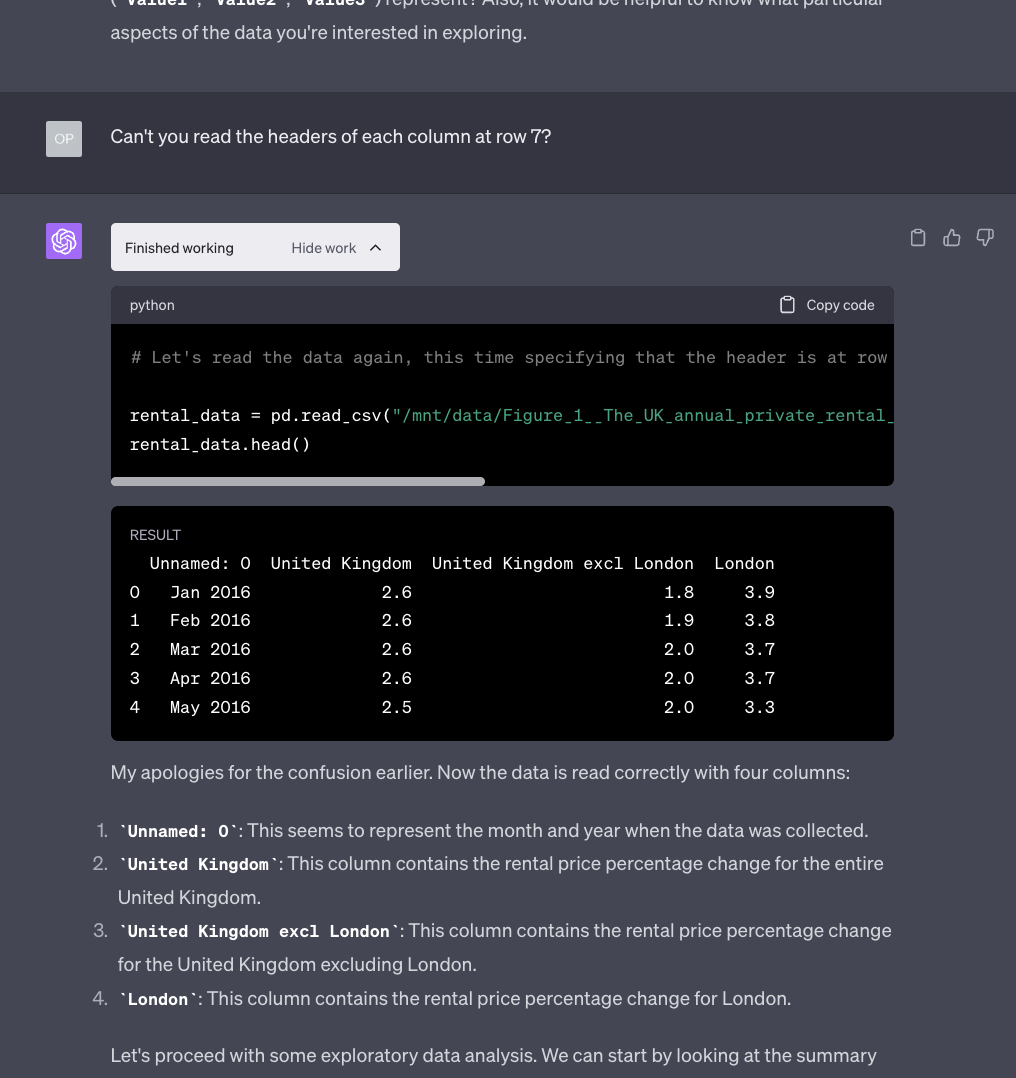
Very frustrating. The reason why I am showing all of this rather than a perfect prompt that avoids all these issues, like I did in the previous section of the newsletter, is to demonstrate the enormous gap between the hype generated by “The AI Guy” on social media and the reality.
Nothing that will not be solved in the future. Let’s get to the actual data analysis.
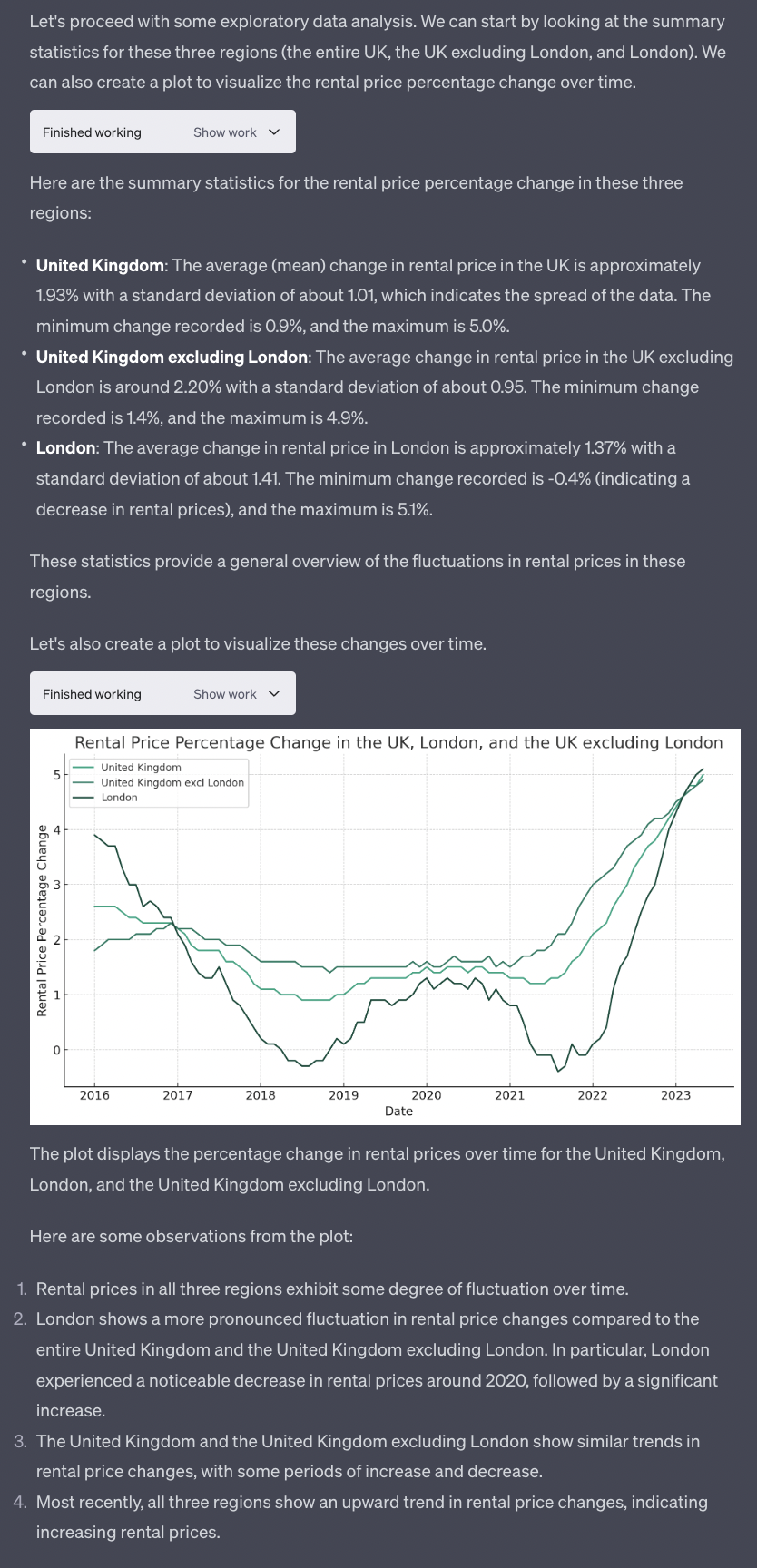
Now this starts to become interesting.
Below you’ll see a zoom of the chart generated by GPT-4 with Code Interpreter followed by, for reference, the chart generated by the UK government using the same data:
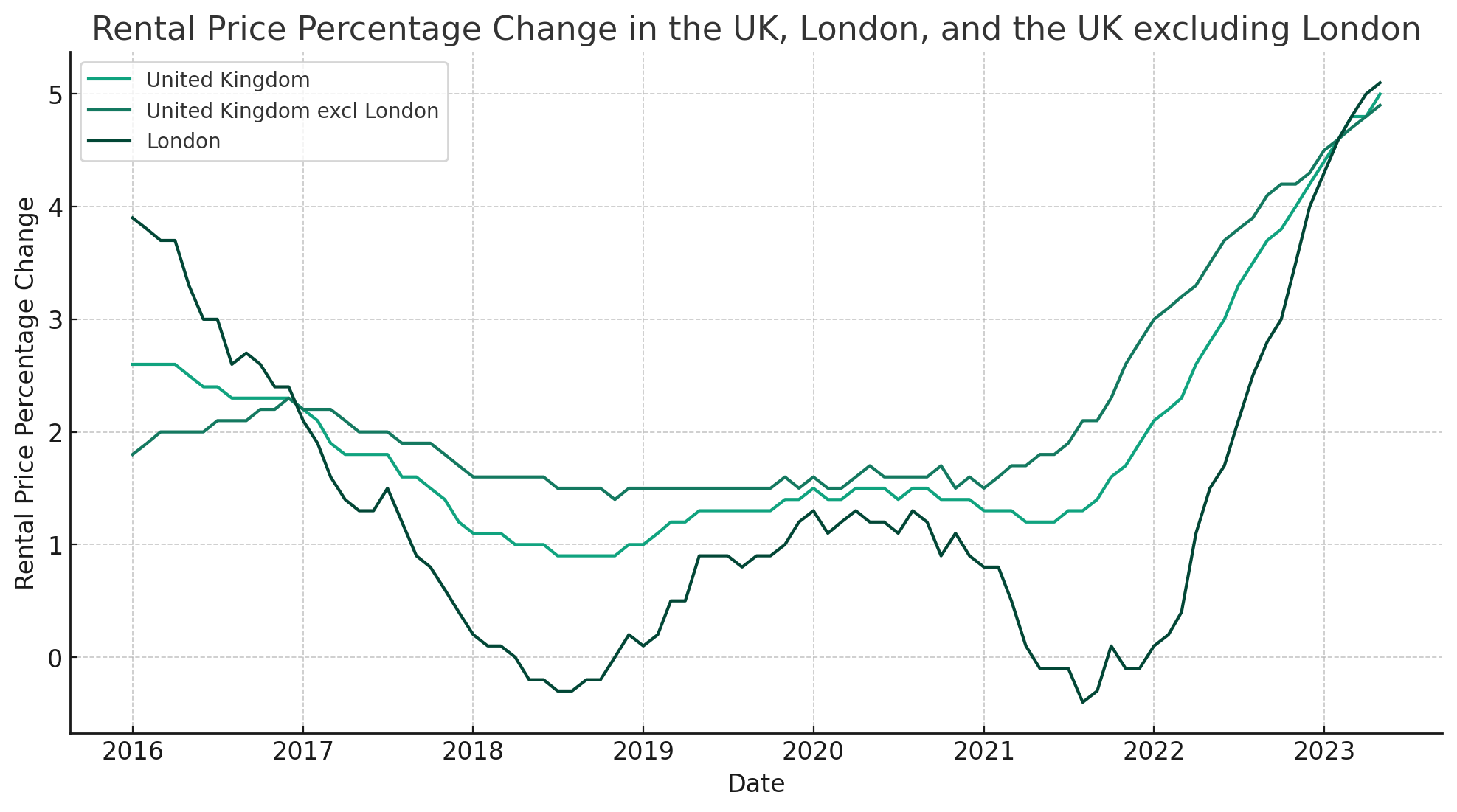
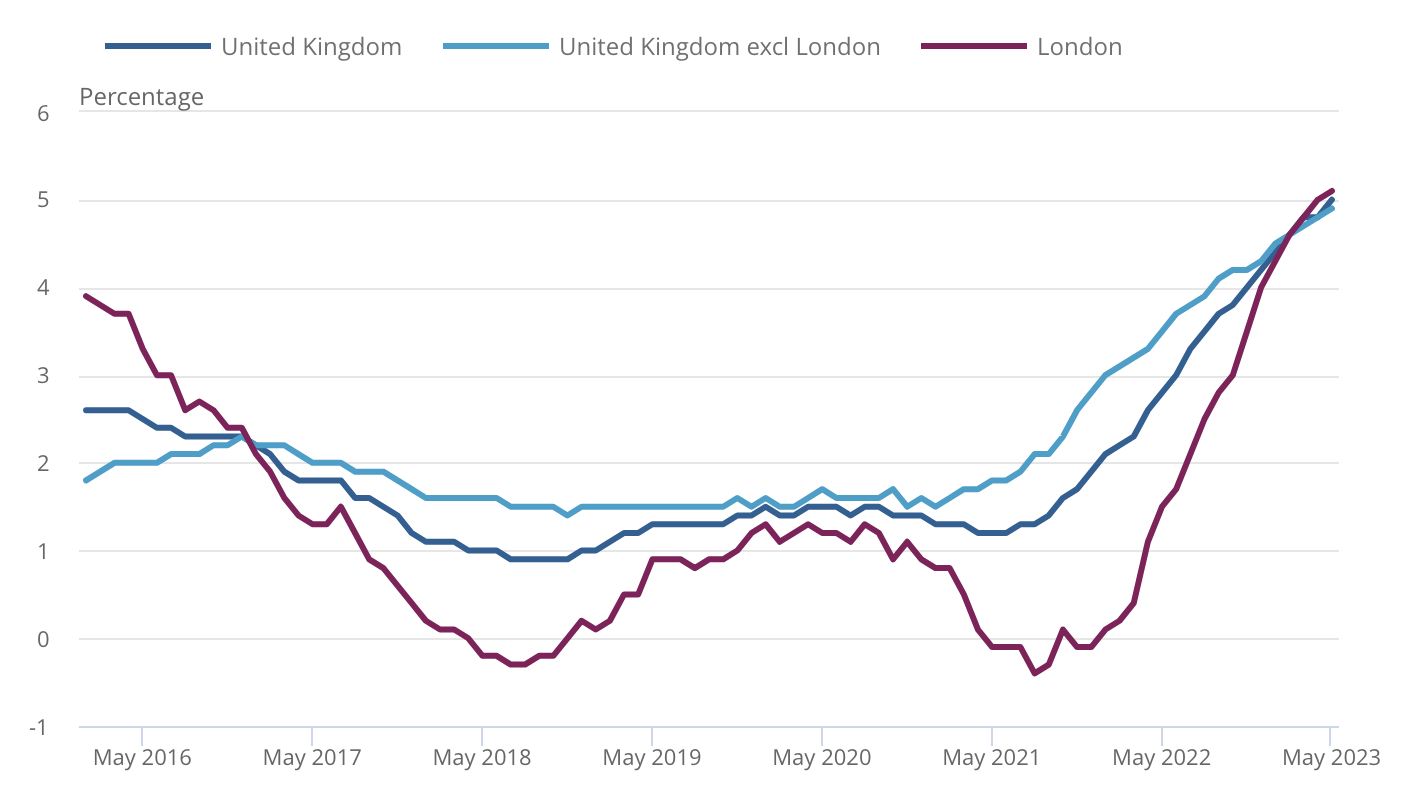
There is plenty of things that we can ask GPT-4 with Code Interpreter to do with this chart. With enough time, we could make the two charts look identical if we’d like to do so. But it’s not the purpose of today’s newsletter.
Before we go any further, let’s see how Claude 2 behaves with the same identical prompt:

Always watch out for hallucinations. Claude is more prone to them than GPT-4.
But, can it generate a chart like GPT-4 with Code Interpreter does?

It seems like it’s trying, but nothing comes out. A bug? Let’s be more explicit:

Nope. No charts for now. But, as you have seen, Claude 2 is very promising and I would keep an eye on it.
And now, let’s go back to GPT-4 and do something way more exciting. Let’s investigate absurd hypotheses.

Yes. I have no shame. GPT-4 knows no shame, so we are a perfect match:
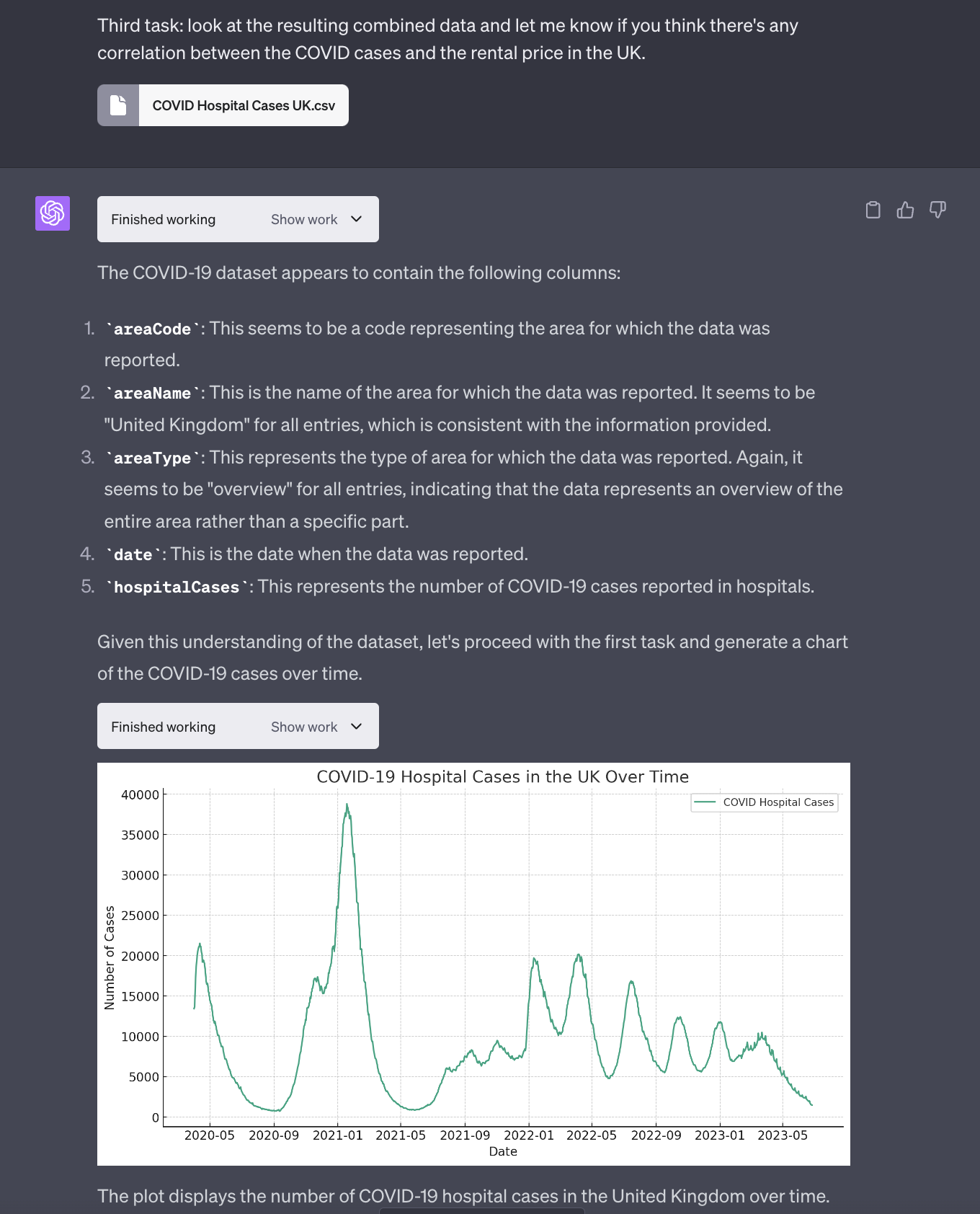
Notice how, this time, GPT-4 with Code Interpreter has no problem extracting the data from the CSV file, generating a lovely chart.
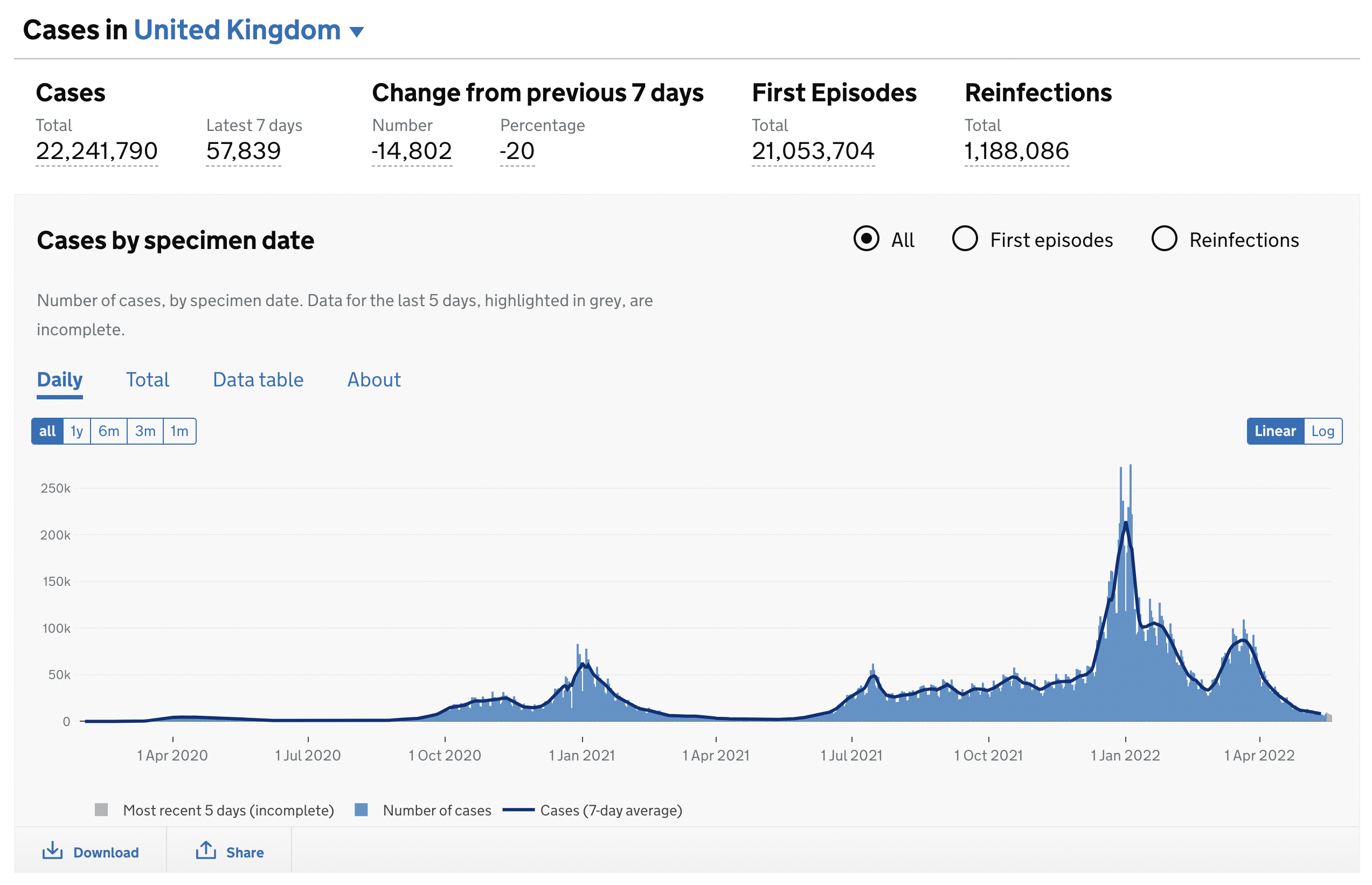
For reference, this is the official data coming from the UK National Health Service (NHS), and this is their official chart from that data:
And now, let’s check this absurd hypothesis:
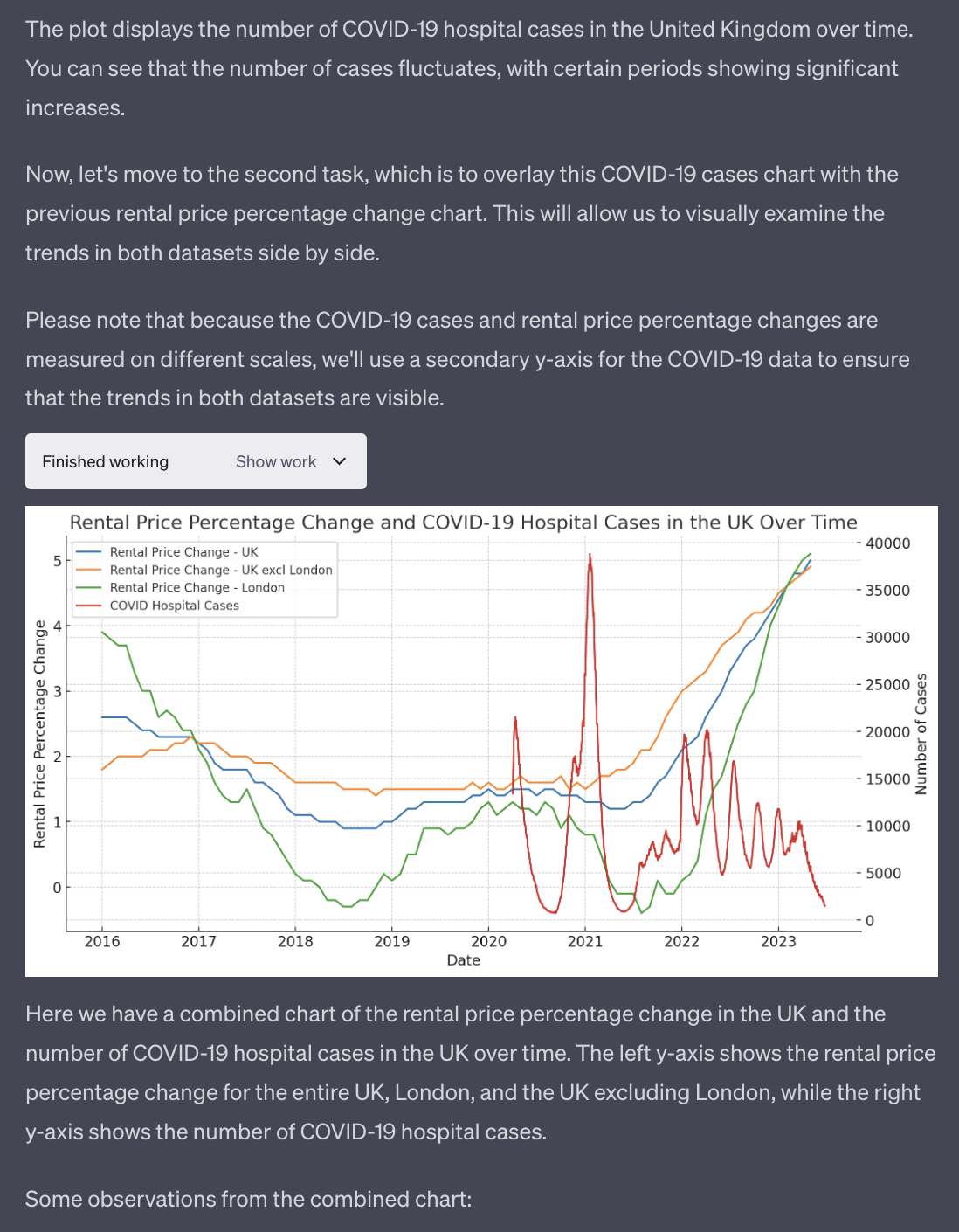
This overlapping chart is the stuff of dreams for somebody that is not a data analyst or a software developer.
The fact that GPT-4 allows us to overlap two arbitrary sets of data without any particular manipulation in a spreadsheet or more sophisticated tools is remarkable.
Let’s see what else the AI can tell us:

Of course, I want a statistical analysis of my absurd hypothesis!
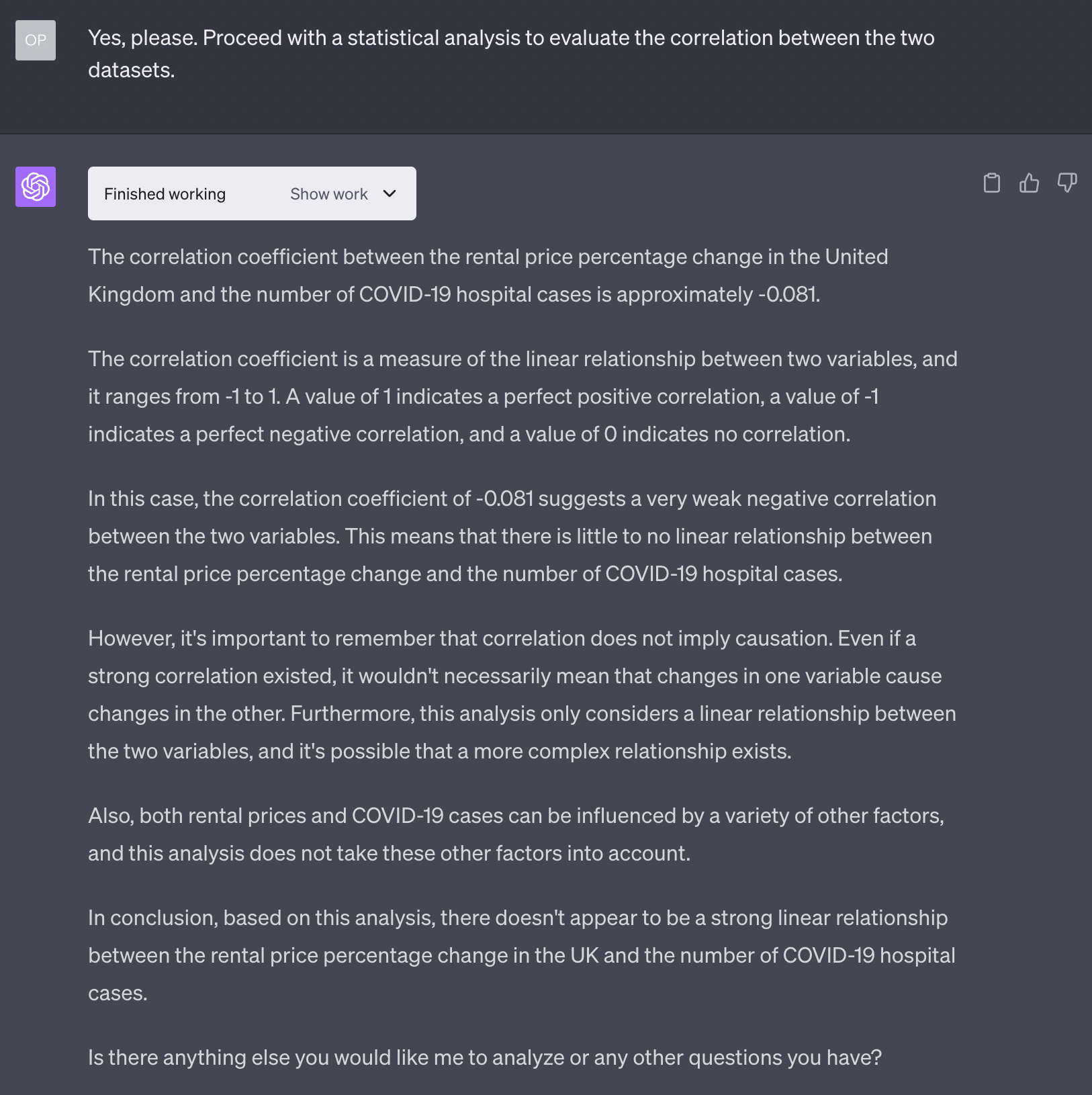
Bummer. I was so sure I discovered something incredible.
But no matter. Next time. I have certain ideas about Egyptians and Pokemons that I want to investigate.
Apologies to all business analysts and data-driven professionals that have read this. No dataset was harmed in the making of this newsletter.