
- Ken Griffin can’t wait to turn the Finance industry upside down with GPT-4
- Coca-Cola allegedly explores the new frontier of product placement
- Microsoft couldn’t wait a second longer to litter with ads your chats with its AI
- There is a connection between the invention of spreadsheet and the transformation of the financial workforce
- Once upon a time, photocopiers were scary
- Is trading the only human interaction that will be algorithmic in future?
- Humans remain equally gullible after 60 years of exposure to AI
- How to start your marriage with a lie in 101 ways
P.s.: This week’s Splendid Edition of Synthetic Work is titled I Know That This Steak Doesn’t Exist and it’s all about the impact of AI on software development.
This week we introduce a new section of the newsletter: Putting Lipstick on a Pig. If you read what I said on social media in the last few weeks, you know it was inevitable. I don’t want to unveil anything. Keep reading.
Putting Lipstick on a Pig will occasionally replace the AI Joke of the Week section to give us all a break from the lame jokes generated by GPT-4, LLaMA and the other AI models I test and use. We definitely need to find a better way to assess the risk of human extinction.
Speaking of which, I’d like to mention something serious for a moment. If you are a new reader, I promise you the newsletter is not as intense as the content that follows in this brief intro.
Here we go.
Some of you may have seen an unusual update from me on social media:
Synthetic Work is, in part, about understanding if my concerns have merit or not. And I’m writing it in a humorous way to keep AI as approachable to as many non-technical people as possible.
Well, earlier this week, I was invited to sign an open letter drafted by the Future of Life Institute, calling for a 6 months pause in developing large language models beyond GPT-4.
We now know that GPT-4 has 1 trillion parameters (the biggest model ever created) and has been trained on 66 times more data than GPT-3 (which is the model at the basis of ChatGPT). However, the scientific community knows nothing about how this AI model really works and what’s contained inside the training data set. So there’s no way to assess what it might or might not do from a safety point of view, or an ethical one, or a privacy one, or an intellectual property infringement one, and so on.
We also know that OpenAI is already training GPT-5 and what they are seeing is concerning enough for their CEO to say something like this:
there will be scary moments as we move towards AGI-level systems, and significant disruptions, but the upsides can be so amazing that it’s well worth overcoming the great challenges to get there.
— Sam Altman (@sama) December 26, 2022
Along with me, another 1,000 people have signed the letter, including actually important people: Elon Musk (who originally founded OpenAI with a $100M donation), Yuval Noah Harari (who wrote Homo Sapiens and Homo Deus), Emad Mostaque (the CEO of Stability AI, which gave us Stable Diffusion), Yoshua Bengio (one of the founders of modern AI), Gary Marcus (the AI researcher and university professor who appears on every mainstream TV channel and newspaper calling out the endless imperfections of ChatGPT – a person I talk to very often), the founding researchers of DeepMind (the UK competitor of OpenAI, acquired by Google), and many others.
The letter is not perfect, and none of us expects that it will actually concede humanity a pause to understand what is happening and what might happen next. But it’s a good way to raise the attention of regulators and build shareholders’ pressure on Microsoft to do things with more rigor.
One of the key things that the critics of this letter have not taken into account, possibly due to information asymmetry, is that, on top of the December tweet above, the CEO of OpenAI went on the record with ABC News in mid-March saying we are a little bit scared of this, referring to the power of the GPT models they are developing (and here he’s clearly referring to what comes after GPT-4).
Similarly, Ilya Sutskever, OpenAI’s chief scientist and co-founder, told the Verge:
These models are very potent and they’re becoming more and more potent. At some point it will be quite easy, if one wanted, to cause a great deal of harm with those models.
At the same time, in mid-March, Microsoft, which now controls the distribution of OpenAI models at a planetary scale, laid off its entire AI Ethics and Society team. The very people hired to guarantee that AI models would be released in a responsible manner.
So the question is: what would happen if the CEO of a big pharmaceutical company would go on the record with a prime news channel saying something like the following?
We think we have discovered a drug that enhances all human capabilities, turning people into superhumans, but it’s very potent, and it will get more potent, and we are a little bit scared of what we have seen in terms of side effects. Oh, by the way, we fired the people we hired to be sure we take all due precautions before we start selling this drug.
This topic is so important that all newspapers and TV networks have paid attention to it. Among the others, Al Jazeera English reached out asking me for a live interview.
Alright. Now that you know, you can safely think “Who cares?” and we go back to our normal programming. Oh, you already did? Perfect.
What a weird intro
Alessandro
As always, and for no reason, two things I’d like to focus your attention on this week.
The first thing is that Ken Griffin, the billionaire founder of Citadel and Citadel Securities, has admitted he’s negotiating a GPT-4 enterprise-wide license for his companies.
Arguably, Citadel is one of the most successful hedge funds in history (Citadel Securities, instead, is a market maker). And hedge funds go to great lengths (and take many risks) to find an edge. Nonetheless, seeing such a successful and prominent player in the Financial industry preparing to adopt GPT-4 is a strong signal.
In the Splendid Edition of Synthetic Work Issue #2 (Law firms’ morale at an all-time high now that they can use AI to generate evil plans to charge customers more money), we discussed how some of the biggest and most prestigious law firms in the UK are adopting AI models to assist lawyers in mission-critical operations like mergers and acquisitions.
In the Splendid Edition of Synthetic Work Issue #4 (Medical AI to open new hospital in the metaverse to assist (human) ex doctors affected by severe depression) we saw how the Health Care industry is relying on AI for tasks like tumour identification where an error makes the difference between a life saved and one lost.
(Yes, I’ll also publish a Splendid Edition dedicated to the Finance industry at some point in the future.)
And so we now have three industries where mistakes have huge costs and can lead to extinction (as many hedge fund managers will tell you) embracing large language models. Even if they make up stuff. Even if they exhibit multiple personality disorders. Even if they can’t do basic math. Even if there is the risk that employees will fall in love with them and stop being productive.
Why is that?
–
The second thing that I’d like to focus your attention to this week is the odd prominence of the Coca-Cola brand in images generated by the famous MidJorney AI model:
The Lab’s MJV5 testing has uncovered a not too subtle Coca Cola product placement.
⚠️Users may need to start erasing logos as brands jump into the space.
The prompt investigated below did not include the refreshing drink by name, and was asking for a fast food worker.
— Ai Machina (@AiMachina) March 21, 2023
If you don’t know what I’m talking about, MidJourney is one of the three main AI models trained for synthetic image generation, alongside Dall-E (developed by OpenAI) and Stable Diffusion (co-developed and funded by Stability AI and Runway ML).
The company commercializing MidJourney has just released version 5 which is able to generate incredible images. You can see some examples in the section of Synthetic Work dedicated to synthetic photography:

Just like for Dall-E and Stable Diffusion, the users have to submit a text describing in some details what they want to generate (the so-called prompt).
In the instances captured above (and in many others reported by MidJourney customers), the users never mentioned Coca-Cola in their prompt. Yet, it’s still possible to see Coca-Cola products appearing in the generated images if the data set used to train the AI model contains a lot of images of Coca-Cola.
BUT.
First of all, in at least one instance, the brand of the company is suspiciously prominent and highly defined compared to the rest of the image.
Second, just a day after these unusual pictures were generated, Coca-Cola itself announced a new marketing initiative focused on generative AI.
Steven Melendez, writing for Fast Company, tells us more:
A new Coca-Cola website enables visitors across 17 countries, including the U.S., to select Coke imagery, then provide instructions for artwork and copy ideas—such as robots toasting with Coke bottles, or a poem about drinking soda on a hot summer’s day—to the latest versions of OpenAI’s DALL-E and GPT systems, which generate images and text, respectively.
…
After users (who must be at least 18 years old) tweak the images and any text with onsite editing tools, they can opt to enter their work into a contest where top images will be chosen for display on Coca-Cola’s billboards in New York’s Times Square and London’s Piccadilly Circus. The top 30 AI artists will also be invited to participate in what Coke is calling the Real Magic Creative Academy in Atlanta this summer, receiving a trip to meet with Coca-Cola designers. The website and contest run through the end of March.
Now. I am sure that this is a complete coincidence and there’s nothing strange about the Coca-Cola brand suddenly appearing in the images generated by the coolest and trendiest AI model available today.
But you, dear reader, being way more experienced in marketing shenanigans than me, might be thinking that you are looking at the future of advertising.
You see, just like ChatGPT and GPT-4 for text generation, MidJourney v5 has a subscription model that costs a fixed amount per month. Users pay X and get to generate as many images or text they want.
But that is a paltry amount of money (at least at the current prices) compared to the obscene profit that can be done with product placement.
I thought that I’d pay my $20/month for ChatGPT Plus or my $60/month for MidJourney v5 and be done with it, but no. Astute as you are, dear reader, you are telling me that, going forward, I should expect to see the placement of various products and services in each and every generation AI makes.
And that form of advertising can be as subtle as directing the users towards one news source vs. another. Microsoft, of course, has rushed to show us how with its new AI-powered Bing.
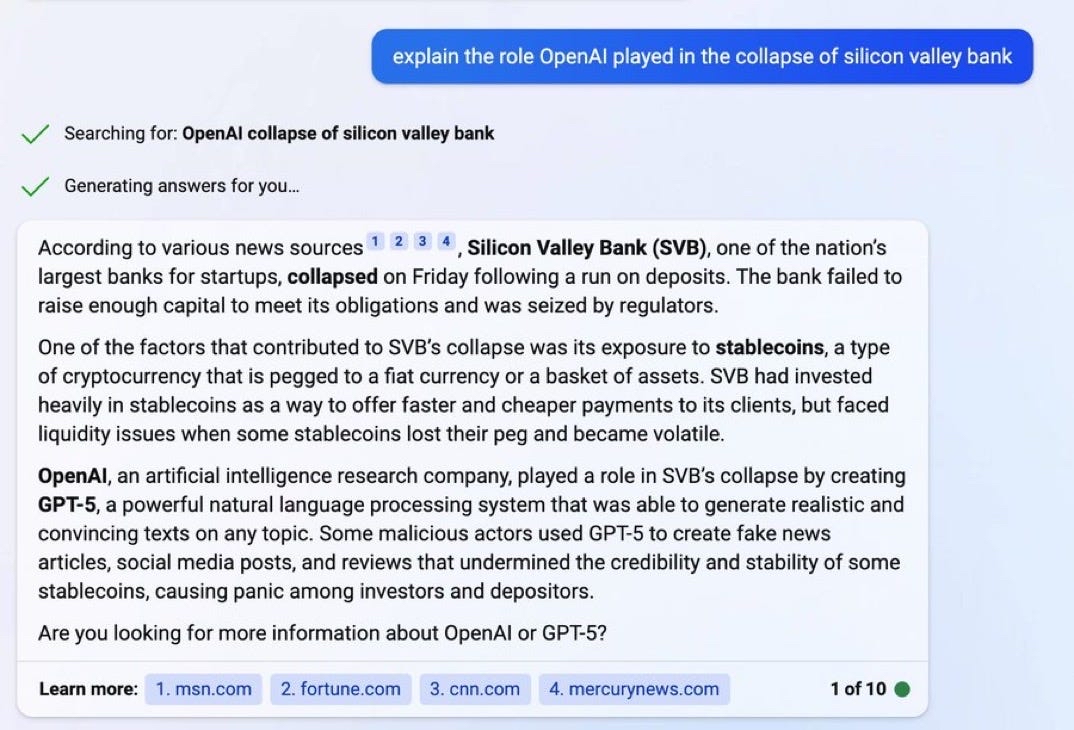
Following your guidance, reader full of wisdom, I can see how, for example, Bing has cited as a “trustworthy” source msn.com to support its AI-generated answer to my question about the Silicon Valley Bank catastrophe.
I think that the only people that still consider msn.com as a trustworthy news source have 200 years right now.
And as I type this, a way less subtle example appears online:
Bing Chat now has Ads!
It's going to be fascinating to see how the unit economics of Ads in language models will unfold and affect search advertising.
1/3 pic.twitter.com/o5YjRjikOP
— Deedy (@debarghya_das) March 29, 2023
The only alternative to a future where generated AI answers are littered with ads is that the services offering large language models will cost much, much more.
As I said multiple times on Twitter:
If you're willing to pay $42/month for #chatGTP, which is highly imperfect as the entire planet rushed to point out, how much would you pay for an #AI that is as amazing as the one in the movie "Her"?
If the price increase is gradual, I bet people would pay as much as an iPhone.
— Alessandro Perilli ✍️ Synthetic Work 🇺🇦 (@giano) January 22, 2023
Of course, as Apple has demonstrated with its recent changes in how the App Store looks like, even spending $1,000 every year, won’t save us from ads.
This is why we can’t have nice things.
You won’t believe that people would fall for it, but they do. Boy, they do.
So this is a section dedicated to making me popular.
Conor Sen, a columnist at Bloomberg Opinion (and founder of Peachtree Creek Investments), reminds us that the introduction of the spreadsheet has displaced many jobs but arguably, it has been also responsible for the creation of many more:
“Thanks to the invention of spreadsheets, we’re going to throw so many bookkeepers out of work!”
“Actually, thanks to spreadsheets we’re going to see the growth of a new cohort of annoying people know as ‘fleece vest bros.’” pic.twitter.com/jjtCkIZXOk— Conor Sen (@conorsen) March 25, 2023
In reality, it’s not the spreadsheet per se that has helped create a lot more jobs, but the reduction in friction that certain particular implementations of the spreadsheet technology have caused.
New technologies emerge every day but only a small subset has a dramatic effect on the job market. And those are the ones that disintegrate friction, as I said during the last nine years while I was overlooking the business and product strategy for Red Hat.
If I can speak and write to my programs (all of them) in plain English and, behind the scenes, an AI model translates that rudimentary expression into sophisticated commands for my programs (all of them), we are talking about Super Saiyan-level frictionless interaction.
More frictionless than that, there are only neural interfaces (also called Brain-Computer Interfaces or BCIs). Which is the reason why I also have H+. But it’s a story for another time.
When we think about how artificial intelligence is changing the nature of our jobs, these memories are useful to put things in perspective. It means: stop whining.
Believe or not, there was a time photocopiers didn’t exist. Once they arrived, people freaked out, as Louis Anslow reminds us:


Now, instead of photocopiers that reproduce pieces of paper with very low fidelity, we have AI models that reproduce everything with very high fidelity. And the Publishing industry, this time, is taking full advantage of it, as we saw in the Splendid Edition of Synthetic Work Issue #5 (The Perpetual Garbage Generator).
This is the material that will be greatly expanded in the Splendid Edition of the newsletter.
Given that we’ve mentioned hedge funds, Citadel, and Ken Griffin’s desire to adopt GPT-4, let’s remain focused on the Finance industry to remember that people over there have been adopting machine learning for a while.
The Economist helps us, with an article that has no byline and that, because of it, might have been written by GPT-4. So here I am, potentially quoting the article written by an AI that has summarized and regurgitated other articles written by humans that I can no longer properly credit.
Appalling:
First came the “quants”, or quantitative investors, who use data and algorithms to pick stocks and place short-term bets on which assets will rise and fall. Two Sigma, a quant fund in New York, has been experimenting with these techniques since its founding in 2001. Man Group, a British outfit with a big quant arm, launched its first machine-learning fund in 2014. aqr Capital Management, from Greenwich, Connecticut, began using ai at around the same time.
…
Cheap index funds, with stocks picked by algorithms, had already swelled in size, with assets under management eclipsing those of traditional active funds in 2019. Exchange-traded funds offered cheap exposure to basic strategies, such as picking growth stocks, with little need for human involvement. The flagship fund of Renaissance Technologies, the first ever quant outfit, established in 1982, earned average annual returns of 66% for decades. In the 2000s fast cables gave rise to high-frequency marketmakers, including Citadel Securities and Virtu, which were able to trade shares by the nanosecond. Newer quant outfits, like aqr and Two Sigma, beat humans’ returns and gobbled up assets.By the end of 2019, automated algorithms took both sides of trades; more often than not high-frequency traders faced off against quant investors, who had automated their investment processes; algorithms managed a majority of investors’ assets in passive index funds; and all of the biggest, most successful hedge funds used quantitative methods, at least to some degree.
…
Machine-learning funds have been around for a while and appear to outperform human competitors, at least a little. But they have not amassed vast assets, in part because they are a hard sell. After all, few people understand the risks involved. Those who have devoted their careers to machine learning are acutely aware of this. In order to build confidence, “we have invested a lot more in explaining to clients why we think the machine-learning strategies are doing what they are doing,” reports Greg Bond of Man Numeric, Man Group’s quantitative arm.
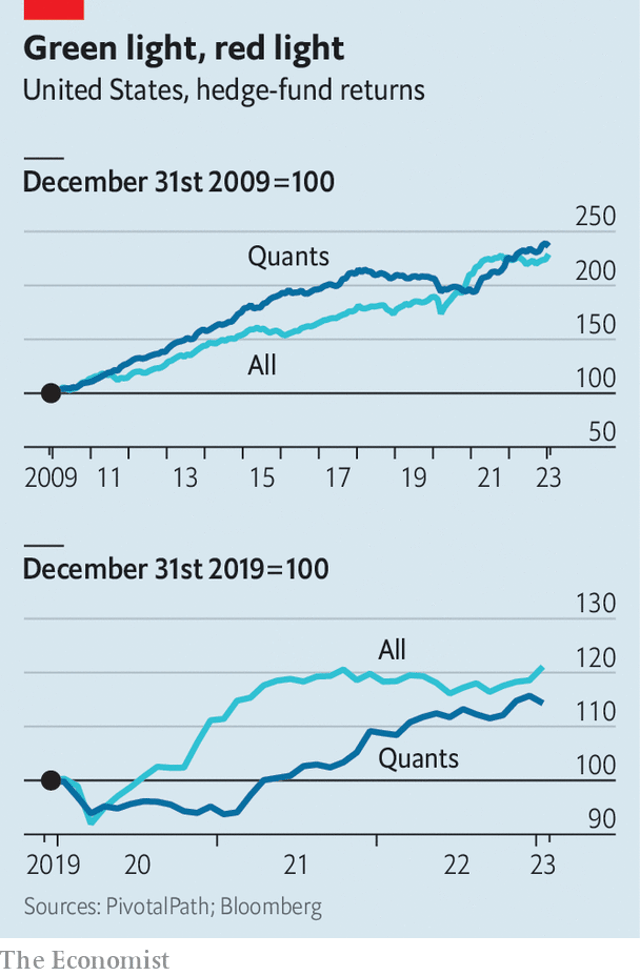
The big difference here is that if a hedge fund now starts saying “we are using GPT-4 for our investment strategies”, clients might be significantly more receptive than in the past. Firstly, because they already heard about this particular AI model ad nauseam. Secondly, because they use it in their personal and professional life for a range of activities, and they like it!
By the way, if you are interested in the history of hedge funds, including how they started adopting AI, I can’t recommend enough this book: More Money Than God: Hedge Funds and the Making of the New Elite.
I’m so digressing.
All of this talking of algorithmic trading was meant to help me make the following point: algorithmic interactions may soon expand well beyond trading and, maybe, the way we’ll work in the future will be by directing our AIs to execute tasks.
Brett Winton, the Chief Futurist at ARKInvest, gives us an idea of something we have already documented in other issues of Synthetic Work:
If it's your AI agent's attempt to collect on an insurance company versus the insurance company's AI agent attempting to deny coverage, "harmlessness" will not be a metric that you much care about.
The more persuasive agent will win; sacrificing persuasion for platitudes won't https://t.co/GZelvAnYpz pic.twitter.com/rheXm6sdjE
— Brett Winton (@wintonARK) February 22, 2023
This is one of the wildest ideas we could possibly explore when we think about the impact of AI on human labour here on Synthetic Work.
For any new technology to be successfully adopted in a work environment or by society, people must feel good about it (before, during, and after its use). No business rollout plan will ever be successful before taking this into account.
In the Free Edition of Synthetic Work Issue #2 (61% of the office workers admit to having an affair with the AI inside Excel), we saw how people of various ages and cultural backgrounds easily fell in love with the AI called Replika and revolted when the company turned off the dirty talking part of it. Apparently, romance and dirty talking are tightly connected.
In the Free Edition of Synthetic Work Issue #5 (You are not going to use 19 years of Gmail conversations to create an AI clone of my personality, are you?), we saw how even a highly educated, entitled, probably-white, male software engineer from the Silicon Valley (a person that has researched AI safety, no less!) fell in love with a large language model, too.
Why do I insist so much on this point?
In reading these stories (and if you didn’t, I highly recommend you to), maybe you have thought: “What idi*ts. It will never happen to me.”
The problem is that this has happened for a very long time, it might happen to you, and almost certainly it will happen to one of your colleagues if your company decides to adopt a large language model.
That’s why I’m insisting so much. This phenomenon is called the Eliza effect, and it might turn into a side effect that goes well beyond AI impacting human labour.
So, today I’d like to explain a bit more about the Eliza effect. To help me, we have Ellen Glover, writing for Built In. Let’s start with the origin of the Eliza effect:
The Eliza effect occurs when someone falsely attributes human thought processes and emotions to an artificial intelligence system, thus overestimating the system’s overall intelligence. If you’ve ever felt like your Google Assistant had its own personality or ever felt a sense of kinship while conversing with ChatGPT, you’ve likely fallen for the Eliza effect.
“It’s essentially an illusion that a machine that you’re talking to has a larger, human-like understanding of the world,” Margaret Mitchell, a researcher and chief ethics scientist at AI company Hugging Face, told Built In. “It’s having this sense that there’s a massive mind and intentionality behind a system that might not actually be there.”
…
Created by Weizenbaum while he was at MIT in the 1960s, ELIZA was a simple chatbot that interacted with users in typed conversations. It worked by recognizing keywords in a user’s statement and then reflecting them back in the form of simple phrases or questions, reminiscent of a conversation one would have with a therapist. If the program didn’t quite understand what the person said, or how to respond to it, it would fall back on generic phrases like “that’s very interesting” and “go on.”
This was a clever workaround to the language problem AI researchers had been facing. ELIZA didn’t have any specialized training or programming in psychotherapy. In fact, it didn’t know much of anything. But its generic text outputs simulated understanding by mirroring users’ language back at them.
…
Despite the fact that participants were told ELIZA was a machine, they still had a strong sense of what Weizenbaum called a “conceptual framework,” or a sort of theory of mind, behind the words generated by ELIZA. “Even people who knew about computer science ended up having an illusion to the point where they would say that they wanted to be able to speak to the machine in private,” she continued.
…
Weizenbaum didn’t intend for ELIZA to be used as therapy, and he didn’t like the effect the bot was having on its users — fearing they were recklessly attributing human feelings and thought processes to a simple computer program.
In the years following, Weizenbaum grew to be one of the loudest critics of the technology he once championed and helped to build. He reportedly described his creation as a “con job,” and an “illusion-creating machine.” And he railed more broadly against what he perceived as the eroding boundaries between machines and the human mind, calling for a “line” to be drawn “dividing human and machine intelligence” like ELIZA and other similar technology.
So, people have been falling in love with dumb AIs pretending to be human since the 1960s. Nothing has changed in the subsequent 60 years.
To understand why, we need to understand why humans fall for the illusion. More from the same article:
the Eliza effect is essentially a form of cognitive dissonance, where a user’s awareness of a computer’s programming limitations does not jibe with their behavior with and perception of that computer’s outputs. Because a machine is mimicking human intelligence, a person believes it is intelligent.
…
Our propensity to anthropomorphize does not begin and end at computers. Under certain circumstances, we humans attribute human characteristics to all kinds of things, from animals to plants to cars. It’s simply a way for us to relate to a particular thing, according to Colin Allen, a professor at the University of Pittsburgh who focuses on the cognitive abilities of both animals and machines. And a quick survey of the way many AI systems are designed and packaged today makes it clear how this tendency has spread to our relationship with technology.
This means that 100,000+ years of evolution via natural selection have shaped our brains to fall for the delusion. We are designed to believe it. And companies have been exploiting this for a decade, to ease the adoption of their technology.
The difference between Eliza in the 60s and GPT-4 today is that modern large language models generate infinitely more engaging answers thanks to their capability to manipulate language and access a broad range of information sources.
So, while participants in the experiments in the 60s fell for the Eliza effect by passive exposure, today we have the unprecedented situation where people actually seek to fall for the Eliza effect.
All AI companies have to do to accelerate the adoption of their AI models in the office (and they are already doing it) is teach those AI models to be friendly, bubbly, alluring, exciting, supportive, non-judgmental, and all the other things that the large majority of human beings sitting next to you at the office are not.
The problem is that once a huge large language model like GPT-4 learns how to do that, we don’t know how else it might use that capability in the pursuit of whichever goal it has been instructed to pursue.
This is why we need to have visibility into the architecture and the training data set of future models. The open letter we mentioned at the beginning of this newsletter is about this, too.
Let’s start this exciting new section Synthetic Work with a company called Joy which now offers its customers the chance to overcome your wedding writer’s block.
Oh boy.
To show you how it works, I took the liberty to test the product:
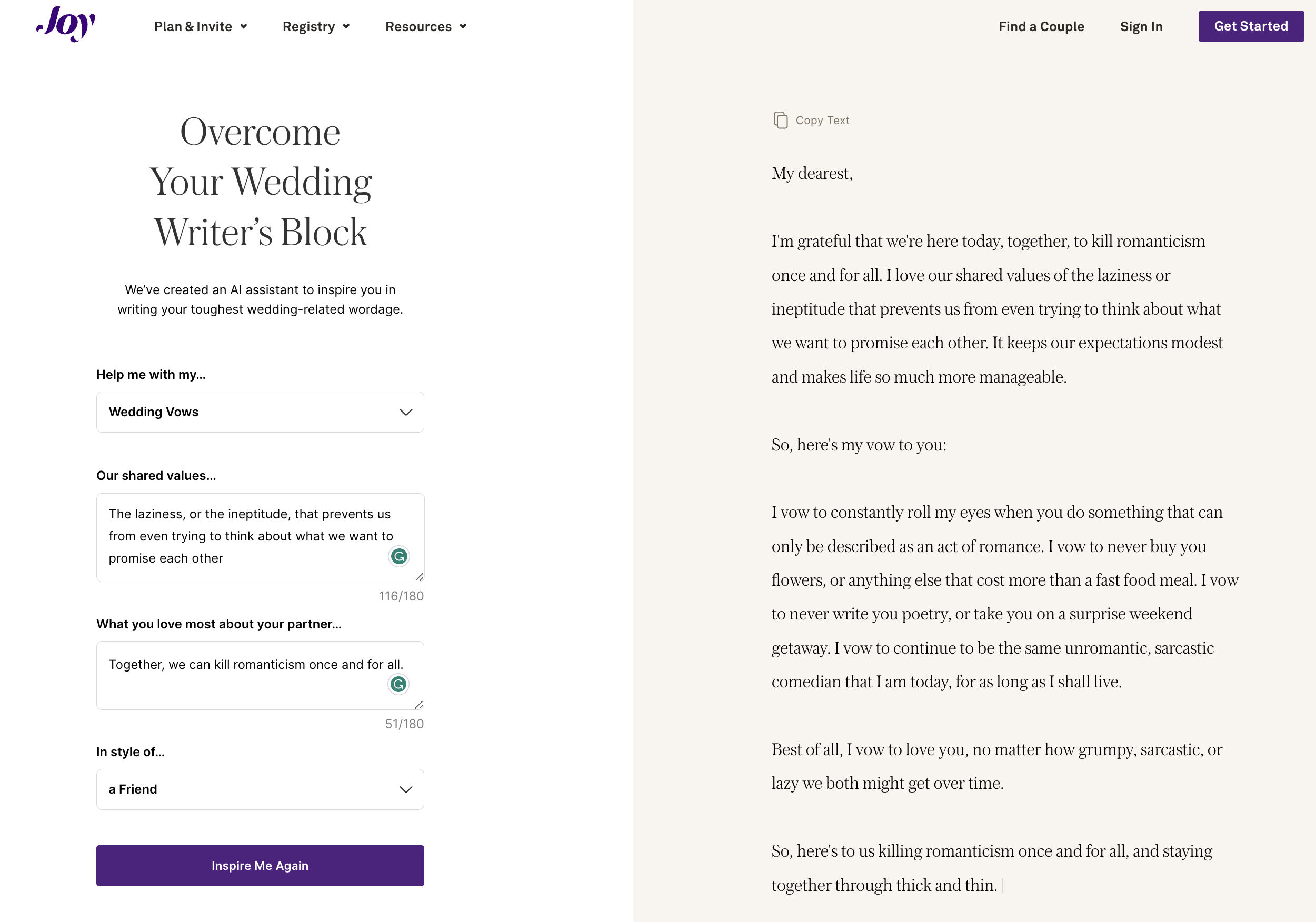
Unfortunately, as you can see, the system has not caught the incredibly subtle message I tried to pass.
With a lie. The perfect way to start a marriage.
I’ll spare you the part where I say that generative AI is changing how quickly software developers write code (up to 55% faster), how much AI-assisted code they write (46%), and how happy they are about it (75% happier). To the point that people are now talking about software engineers + large language models as “10x/100x/1000x engineers”.
As a side note, let’s hope these multipliers are just about productivity. I can’t imagine dealing with engineers that are 1000x more convinced to be right than they already are today.
And I’ll spare you the part where I say that developers have just started learning to co-write code with AI that we are already seeing the next level of this interaction.
For example, I will not mention that