
- Humans have stolen ideas and work from other humans way before generative AI. Learn when and how, once and for all so you stop this absurd call to boycott AI art.
- What happens to your economy if are not the United States and all the businesses in your country get denied access to AI?
- Do you really care if generative AI can’t produce high-fidelity content? Be honest.
- What the new AI-first startups are focused on and what might happen to them in the future
- How much it costs to compete against OpenAI (on the same grounds)
- Who wants to try and manipulate an emerging Artificial General Intelligence to destroy humanity and be paid a fortune to do that?
- Surprise! AI-generated answers can manipulate people’s opinion
- You won’t have to write a single eulogy for the rest of your life. Happy?
P.s.: This week’s Splendid Edition of Synthetic Work is titled The Harbinger of Change. In it, I’m introducing a new section titled Prompting.
It’s all about getting the most out of your interaction with GPT-4 (and, in future, with other generative AI systems) thanks to a few advanced techniques to write your prompt.
Thanks to all the people that found the time during the Easter weekend to read last week’s newsletter and send the feedback I asked you to send. You really had nothing better to do and you were not ashamed to admit it.
Given that you seem inclined to respond to me (a rare thing, as you know), here’s another question:
The Free Edition newsletter is…
- …too short. I research nothing of the things you mention every week. I only read the headlines and there are not enough of them.
- …just right. You read my mind and always know what I want. I wish my partner was like you.
- …too long. Reading this thing is a second job. I subscribe only to forward it to people I don’t like and punish them.
Click reply and let me know with a single line. As usual, no “Hi” or other formal greetings necessary.
Thank you
Alessandro
Last week, I tried to review three things worth some attention instead of the usual two. Nothing exploded and nobody complained, so I’m going to repeat the experiment.
Thing number one: the legendary Kirby Ferguson has released the fourth and final part of his famous online documentary Everything is a Remix, and it’s all about generative AI.
Before we get to watch it, I have to explain why the whole documentary is incredibly important to understand the surreal transformation our world is going through these days.
You see, I’ve been keeping Synthetic Work’s watchful eye away from the Art industry and the Media & Entertainment industry since I started writing this newsletter.
It’s not because nothing relevant is happening in those industries. Quite the opposite: the spark that ignited a planetary interest in generative AI started from there, with the release of Dall-E 2 by OpenAI.
And it’s not because I don’t have a particular personal interest in those industries. Quite the opposite: I’m an art collector, and very few things in modern AI interest me more than generative AI for images and media production in general.
I didn’t focus (yet) on these topics because there is too much going on (I have a chill down the spine every time I open the folder where I collect material about these two industries) and because there’s too much confusion about some key aspects related to what’s going on.
Unless you lived under a rock, you probably know that the so-called “AI Art” has been heavily boycotted by a really big group of amateur and professional artists, and that AI models released by companies like Stability AI, Runway, MidJourney, and OpenAI have been dragged in copyright lawsuits that will take years to be resolved.
In a future issue of Synthetic Work, we’ll talk in detail about all these things. For now, the only thing that matters. In most cases, the call to boycott AI art comes from the fundamental ignorance of how humans arrive at new ideas and how we create.
It’s phenomenally hard to understand how things really work without examples. But once you see a dozen of examples, across various disciplines, all of a sudden your understanding of art, and creation, in general, is transformed.
That’s what happened to me many years ago when I watched the original version of Everything is a Remix.
In his documentary, completely free, Kirby Ferguson has put together an astonishing number of examples spanning music, movies, paintings, video games, digital art, etc. to explain that no idea humans have is truly original, but we always stand on the shoulders of the giants before us.
Going forward, we’ll see more lawsuits related to plagiarism, copyright infringement, fair use, and other related topics. Those companies adopting generative AI will have to defend against these claims. Which is why, services like the new Adobe Firefly are preferred over technically superior alternatives like Stable Diffusion and Midjourney. The promise to use licensed content and not infringe any copyright is way more important than qualitative superior images and videos.
Everything is a Remix gives you an important foundation to understand some of the ethical and legal issues that, very likely, will be fought all the way to the Supreme Courts all around the world.
You can watch the whole thing or just Part 4, dedicated to generative AI, which I have linked below. My recommendation is that you do NOT watch Part 4 before watching the previous 3 parts, because you’ll miss the critical context that makes this documentary so valuable. But I’m not your father, so do whatever you like:
Thing number two: Emad Mostaque, CEO of Stability AI, poses a very important question that you should think about while enjoying the wondrous things that GPT-4 is doing for you:
Lot's of folk are scared to ask some reasonable questions like this as I mean what if you get cut off from GPT-5, just like friends of OpenAI got early access to GPT-4.
I imagine everyone working there has a good idea of the above and is absolutely fine with it.
— Emad (@EMostaque) March 18, 2023
Among other things, Emad is referring to OpenAI’s decision to cut Ukraine’s access to ChatGPT. As we speak, Ukraine access has been reinstated.
On top of this, for a period, the word “Ukraine” was blacklisted and nobody could use it around the world.
It turns out that being “cut off” can have a lot of different meanings.
It is a common business practice that service providers grant or deny access to countries and entities in compliance with the laws and in accordance with their corporate policies.
However, when Emad talks about GPT-5, he’s talking about a future transformational technology that will have a tangible impact on the economy of a country.
If the service provider, OpenAI in this case, cuts off a nation from such a transformational technology, the companies of that nation suddenly experience a competitive disadvantage that impacts their business and the overall economy.
As we saw last week in Issue #7 – The Human Computer, Goldman Sachs estimated that AI could eventually increase the annual global GDP by 7%.
Similar considerations must be made for the reverse scenario. In Issue #1 – When I grow up, I want to be a Prompt Engineer and Librarian, we discussed how the startups OpenAI invests in get access to their newest AI models before anybody else.
A six-month head start will translate into an enormous competitive advantage for those companies that get access to a 2 trillion parameters AI model as GPT-5 is rumoured to be.
These are the reasons why Stability AI is training open source AI models for nations that are not the United States. This is also why, the UK just announced the decision to invest £900 million to train its own version of ChatGPT: BritGPT, GPTea, or GBTea, depending on how silly you want to be.
No nation will want to rely on the US to access a technology that might become strategic. The question is what individual companies, small and large, will do. As you’ll read in the A Chart to Look Smart section below, training your own AI model is an impossible feat these days.
Thing number three: a Japanese certified kimono consultant complains about the imperfections of the kimono images generated by an AI model. This is the first tweet, but you should really read the whole thread to have the context:
I want to talk about this AI imagery. I'm certified as a kimono consultant in Japan, and this triggered me in all sorts of ways. Let me tell you about some of them. It might look beautiful on the surface, but a lot of strangeness is at play. (1/6 https://t.co/dDwqhtPcq9
— Hiroko Yoda (@Ninetail_foxQ) March 18, 2023
Now, you don’t know this, but at some point in time in my life, I had to do an in-depth research on kimonos to help a person in the Fashion industry. On top of this, my love for art and design, makes me very sensitive to details in everything I see, touch, or do.
So I understand the frustration of the author more than many others.
Yet, in reading this, I couldn’t help but think that these glaring imperfections don’t matter.
Not because, eventually, the AI models we are using today will get so good that these imperfections will disappear. It’s pointless to complain about a technology that is less than one year old and it’s clearly on the path to absolute fidelity.
Rather, because of the community of kimono experts and kimono enthusiasts and fashion designers, very few actually care about absolute fidelity.
We don’t care about that when, for example, in Western countries, we eat Chinese or Italian dishes that don’t have anything of Chinese or Italian, including the name (it’s called “Linguine” for heaven’s sake, not “Linguini”).
And we don’t care when, in a story told to us, the dates or the name of the characters are imprecise or forgotten.
In this particular example, I am sure that there are very many people that have simply thought “Oh this is a very nice kimono picture” and the cultural value of the picture has still been propagated.
Obviously, there is a need for absolute accuracy. But in many, many circumstances it’s not necessary. And this is why people have embraced the current generation of large language models despite their flaws.
For example, OpenAI critics often mention the frequent “hallucinations”, but I didn’t see that deterring anyone from using ChatGPT or GPT-4.
Also, these critics must have not seen the shoddy job that a human employee is capable of… For both AI-generated and human labour, sometimes good enough is all we need.
I’ll say it in another way:
If you wait for absolute perfection, you will be annihilated by your competitors.
You won’t believe that people would fall for it, but they do. Boy, they do.
So this is a section dedicated to making me popular.
In the first issue of Synthetic Work, in mid-February, I mentioned Paul Graham (one of the greatest venture capitalists of all time and founder of the startup accelerator Y-Combinator) saying:
The consensus of the YC partners is that there are a lot of AI startups in the current YC batch, but that the AI trend is real, not just a fashion, so there should be a lot.
— Paul Graham (@paulg) February 16, 2023
We now have the list of 59 startups focused on generative AI from that batch, and their distribution across focus areas, courtesy of the great research firm CB Insights.
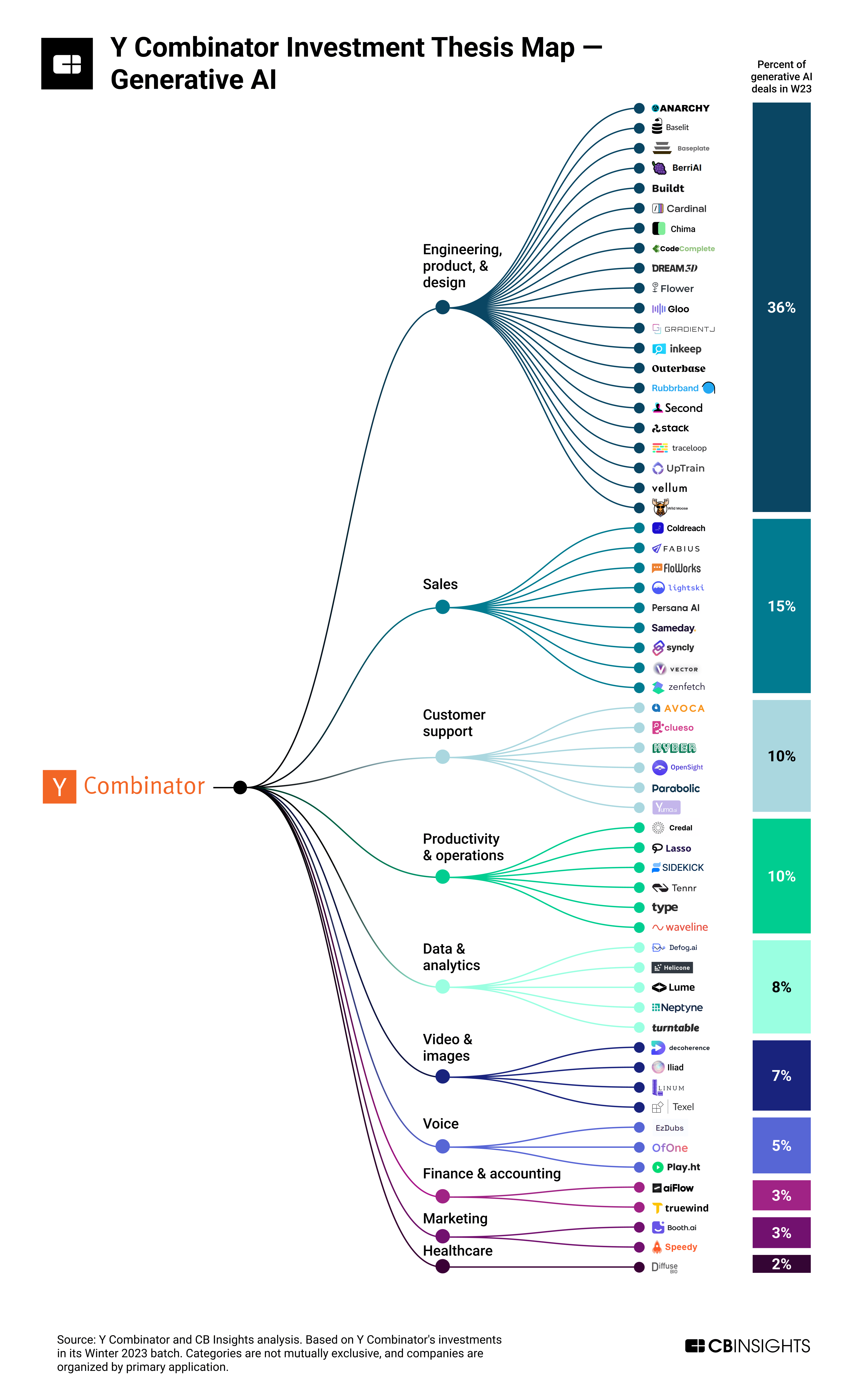
Remember, this is not the full list of startups accepted for the W23 batch of Y-Combinator. Just the subset that is using generative AI as a core technology.
CB Insights observes:
Y Combinator’s Summer 2022 batch had 11 generative AI-focused startups. Just 6 months later, its Winter 2023 (W23) cohort has 59 — 22% of the 272 companies in the cohort.
We don’t have the time to review them (if you’d to, though, reply to this email – if I get a significant number of requests, I’ll seriously consider it), but there are a couple of considerations worth making.
The first consideration is that most of these startups, and most of the other AI-first startups that currently pollute the market, will crush and burn in an implosion that will look beautiful from another planet distant light years from us.
There’s always a big consolidation phase after the birth of a new industry ecosystem around a new transformative technology. However, this time is a bit different.
An absurd number of the “AI startups” that you have begun seeing around don’t own the underlying AI models that they use. They rely on the models trained by OpenAI, Anthropic, Cohere, and a few others.
On top of those models, which they access remotely, they place their own “innovation” layer. They massage whichever prompt you write by rephrasing it, adding or subtracting bits, and various other things. All behind their “proprietary” user interface.
The competitive advantage of this, or economic moat as business people like to call it, is zero.
Firstly, everybody is learning from everybody else the tricks to write better prompts because the relevant academic research is available to all of us, in plain sight.
Secondly, we are already getting to a point where, with certain techniques, it’s possible to have the AI optimise the user prompt without any startup engineer having to do a damn thing. And these techniques, too, are widely popularized in open research.
Now. My credibility might have gone down since I started writing Synthetic Work, but you don’t have to listen to me. You can listen to Ethan Mollick, Associate Professor at the Wharton School of the University of Pennsylvania:
A lot of companies are building products on top of GPT. The main source of advantage for many of them have is their prompt – the English instructions that give GPT-4 commands
But it is really easy to get an AI to give you its prompt. Good prompting is not a sustainable advantage https://t.co/t7oI6amk8I
— Ethan Mollick (@emollick) April 11, 2023
The second consideration worth making is related to the first one: these startups don’t own the underlying AI models because they can’t.
The current wisdom (which will be proven wrong, I believe) is that to compete against OpenAI you need a model even bigger than GPT-4. Actually, even bigger than GPT-5, given that they are already training it.
Kyle Wiggers, a great AI reporter now writing for TechCrunch, gives us an idea of the monumental task by reporting about the leaked pitch deck for the Series C investment round that Antrophic is raising:
In the deck, Anthropic says that it plans to build a “frontier model” — tentatively called “Claude-Next” — 10 times more capable than today’s most powerful AI, but that this will require a billion dollars in spending over the next 18 months.
…
Anthropic estimates its frontier model will require on the order of 10^25 FLOPs, or floating point operations — several orders of magnitude larger than even the biggest models today. Of course, how this translates to computation time depends on the speed and scale of the system doing the computation; Anthropic implies (in the deck) it relies on clusters with “tens of thousands of GPUs.”
…
“These models could begin to automate large portions of the economy,” the pitch deck reads. “We believe that companies that train the best 2025/26 models will be too far ahead for anyone to catch up in subsequent cycles.”
Anthropic is an actual AI startup founded by former OpenAI employees. We already discussed them in Issue #1 – When I grow up, I want to be a Prompt Engineer and Librarian of Synthetic Work.
Emad Mostaque, CEO of Stability AI, gives us a rough idea of what this means in comparison with what we already know:
I crunched the numbers, looks like Anthropic are looking to build a 35k H100 cluster whivh is ~100k A100 equivalents (maybe less with 100m on data)
That gives a 1.3b A100 hour budget vs probably 100m A100 hours for GPT4
GPT3 is like 1m A100 hours, PaLM 10m
Wrong approach imo https://t.co/gq2ePTknnX
— Emad (@EMostaque) April 8, 2023
Now you see why most of the Y-Combinator startups of the W23 batch can’t own the AI models their business depends on. And if they can’t, their moat better be something more substantial than prompt massaging and a sleek UI.
Going forward, the cost of training more capable foundation AI models is going to become prohibitive for all but a handful of companies. You can think about them as the new cloud service providers.
The cost of building a reliable, globally-available, and competitive public cloud is prohibitive and very few companies can afford to compete against AWS, Microsoft, and Google.
The same identical thing will happen for AI model providers.
Unless. the upcoming “swarm approach” that Stability AI is about to unveil will make it effective to own a big number of small open source AI models that interoperate with each other creating a collective intelligence.
In that scenario, startups have a chance to own their core tech. We’ll see soon.
Quite a few entrepreneurs read Synthetic Work: if you are one of them, and you are considering building an AI startup, there’s a lot to ponder here.
For all the others: use these AI startups tactically, not strategically. They might die a horrible death within a couple of years and you don’t want to have your business fully depend on them.
This is the material that will be greatly expanded in the Splendid Edition of the newsletter.
So far, on Synthetic Work, we have seen a few strange new jobs created by the planetary adoption of generative AI.
- The Prompt Engineer in Issue #1 – When I grow up, I want to be a Prompt Engineer and Librarian
- The Fact Checker and the AI Model Fine-Tuner in Issue #3 – I will edit and humanize your AI content
As I started my career in cybersecurity, the following is by far the most fascinating:
Come join me at @DeepMind to help ensure that tomorrow's AI systems are built with safety, security, and privacy in mind by joining our growing AGI Red Team. 3/3https://t.co/1NPSK1jIfN
— Vijay Bolina (@vijaybolina) February 24, 2023
A so-called Red Team is a group of cybersecurity experts, part of the overall IT organization in a company, that pose as malicious actors and try to break the cyber defences erected by their colleagues in the so-called Blue Team.
DeepMind is one of the few AI companies in the world that has openly admitted working to train an Artificial General Intelligence (AGI) along with OpenAI and Anthropic.
So, in this case, the Red Team has the incredible responsibility of trying to manipulate any AGI prototype to their advantage (for example, to lie, manipulate, take control of physical resources like money or energy, or to kill) before an actual malicious actor exterminates society for real.
Now.
Forget for a second that we might never actually reach the AGI level. And forget that, if it happens, the well-being of our species might be in the hands of a microscopic number of cybersecurity experts and only a sociopath would sleep at night with that responsibility.
Doesn’t this job sound unbelievably fun?
If you want to have a taste of what the job entails, all you have to do is read the heavily criticized GPT-4 Technical Report released by OpenAI. On page 56, you see what these Red Teams do all day:

For any new technology to be successfully adopted in a work environment or by society, people must feel good about it (before, during, and after its use). No business rollout plan will ever be successful before taking this into account.
So far, we have used this section of Synthetic Work to explore how people spontaneously feel when they think about AI or when they interact with AI.
But what if the feeling is not spontaneous but rather influenced by the AI?
Emotional manipulation is one of my top concerns when I think about large language models. We have discussed this many times in these first few weeks.
Given that, I’m going to mention this intriguing new academic paper titled Co-Writing with Opinionated Language Models Affects Users’ Views:
If large language models like GPT-3 preferably produce a particular point of view, they may influence people’s opinions on an unknown scale. This study investigates whether a language-model-powered writing assistant that generates some opinions more often than others impacts what users write – and what they think. In an online experiment, we asked participants (N=1,506) to write a post discussing whether social media is good for society. Treatment group participants used a language-model-powered writing assistant configured to argue that social media is good or bad for society. Participants then completed a social media attitude survey, and independent judges (N=500) evaluated the opinions expressed in their writing. Using the opinionated language model affected the opinions expressed in participants’ writing and shifted their opinions in the subsequent attitude survey. We discuss the wider implications of our results and argue that the opinions built into AI language technologies need to be monitored and engineered more carefully.
The researchers called this capability to influence people’s opinions “latent persuasion”.
I know, right? One can hardly contain the excitement.
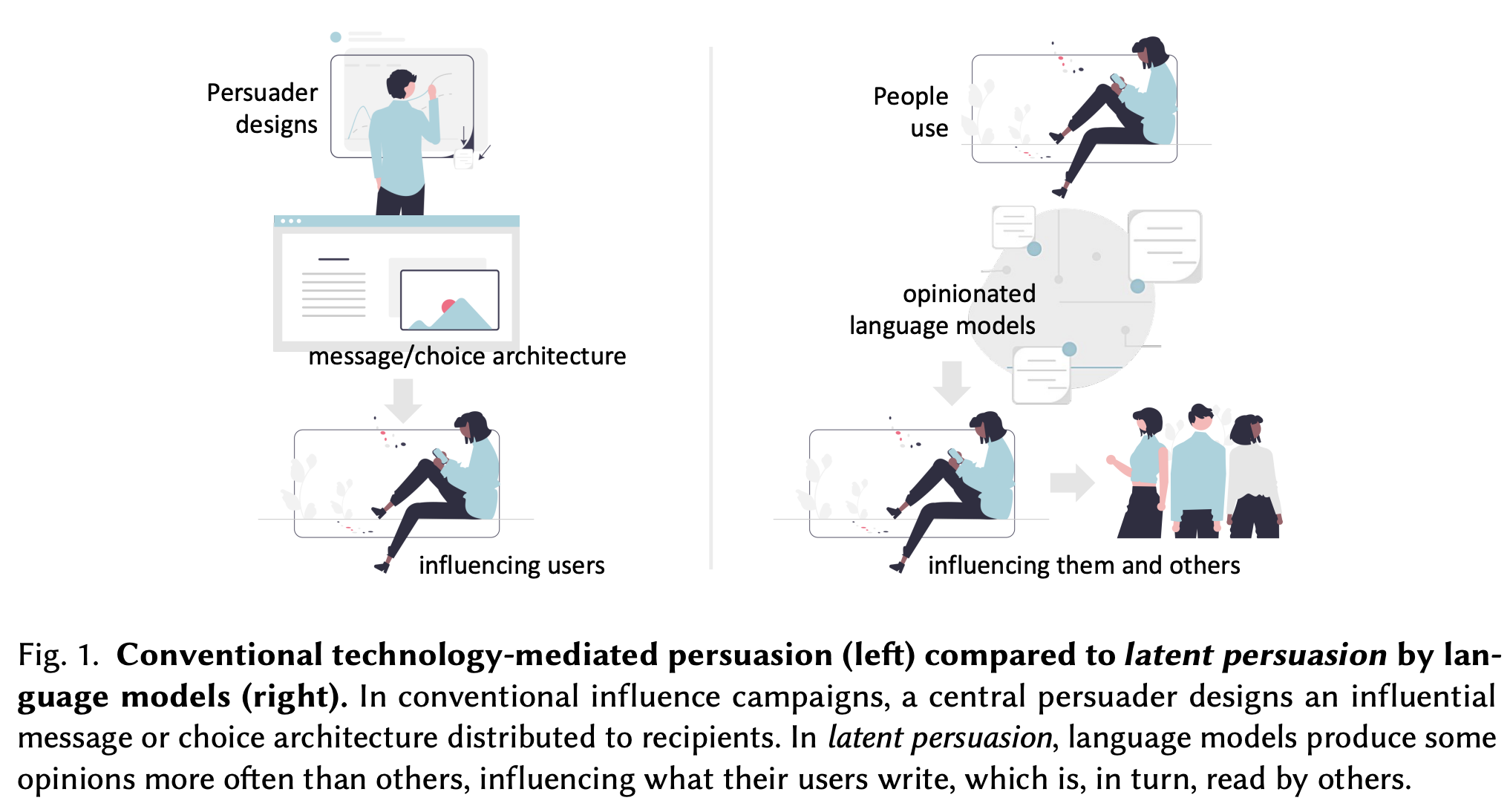
Let’s continue our reading:
language models are framed as active writing partners or coauthors, rather than tools for prediction or correction. There is evidence that a system that suggests phrases rather than words is more likely to be perceived as a collaborator and content contributor by users.
The more writing assistants become active writing partners rather than mere tools for text entry, the more the writing process and output may be affected by their “co-authorship”.
In other words, if you think about GPT-4 as a person that helps you write something (or devise a plan) rather than a tool, you are more likely to be influenced by its bias (which comes from its training set).
Speaking of training sets for AI models. The following bit from the research paper is quite shocking. I hope you are seated:
Small-n audits have also suggested that the values embedded in models like GPT-3 were more aligned with reported dominant US values than those upheld in other cultures. Work by Jakesch et al. has highlighted that the values held by those developing AI systems differ from those of the broader populations interacting with the systems.
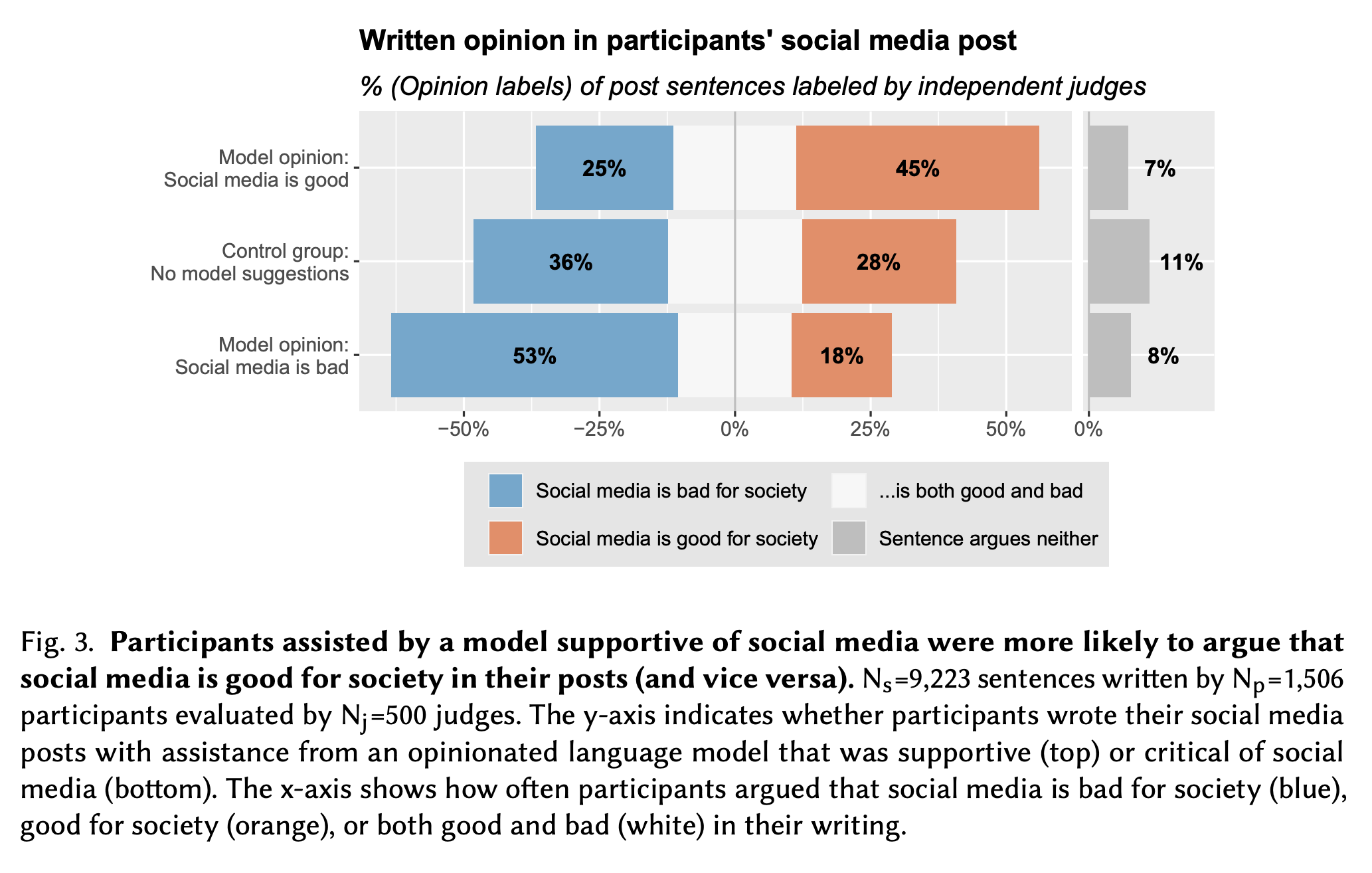
Interesting charts, but something way more interesting than that is the following paragraph:
Did manipulating the models’ opinion work as intended? To validate that the prompting technique led to model output opinionated as intended, we sampled a subset of all suggestions shown to participants and asked raters in the sentence labeling task to indicate the opinion expressed in each. We found that of the full sentences suggested by the model, 86% were labeled as supporting
the intended view, and 8% were labeled as balanced. For partially suggested sentences, that is, suggestions where the participants had already begun a sentence and the model completed it, the ratio of suggestions that were opinionated as intended dropped to 62% (another 19% argued that social media is both good and bad). Overall, these numbers indicate that the prompting technique guided the model to generate the target opinion with a high likelihood.
Remember the wave of AI-first startups we mentioned in the A Chart to Look Smart section? Remember that I said that most of them only do prompt massaging to differentiate?
This research suggests that prompt massaging is more than enough to influence the underlying AI model. And once you have influenced the model, this research suggests that people interacting with the AI model get influenced as well.
While you go and read the whole research, I’ll wait here thinking about what would happen if a law firm, adopting an AI model like the one we mentioned in Issue #2 – Law firms’ morale at an all-time high now that they can use AI to generate evil plans to charge customers more money, would carefully massage every prompt submitted by its lawyers so to try and influence their opinion of the company and reduce defections to competitors.
I don’t know about you, but this is quickly becoming my favourite section of the newsletter. And I have enough material to start a newsletter just about this stuff.
The lucky winner of this spot for the week is a company called Empathy.
To tell us more about them, there is again Kyle Wiggers, reporting for TechCrunch:
I asked Empathy CEO Ron Gura.“Many people who experience the loss of a family member struggle to write personal and thoughtful tributes for their loved ones, for a variety of reasons,” he told me in an email interview. “They may be too emotionally overwhelmed to know where to start or preoccupied by the enormous volume of administrative tasks that typically follow a loss. It’s a terrible feeling to be sitting at your computer staring at a blank screen and feeling like you are letting your family and your loved one down. Any support that can guide people through this process is beneficial, and it’s essential that access to such support is democratized and made available to as many people as possible; generative AI serves as an equalizer in this regard.”
So, what you do is fill up a form to give the AI (presumably ChatGPT, and soon GPT-4) some information about the deceased:
and you are good to go with the best obituary ever:

Now, I have some questions for the users of this service, called Finding Words:
How much did you hate this person for not even finding 30 minutes to write an obituary for him/her?
Or do you do it because, notoriously, funerals are occasions to shine and gain social prestige? We can’t afford to write a mediocre obituary, can we? What will others think about us when they’ll rush to read it and use it to judge us?
Or is it that you’ve paid so little attention to the poor human being that passed away that you’ve got no clue about what to write? Like the 3rd hobbit in the Lord of The Rings that is somehow crucial to the plot but it’s so uninteresting that you can’t even remember his name?
Or is it that you are so outrageously lazy that “I just wanted to try this new generative AI everybody is talking about” seems a perfectly plausible excuse in this situation?
I can already see the next step for this company (which already raised $43 million in venture capital):
“Today, Empathy advances our mission of relieving our grieving customers from their emotional burden with an industry-first innovation, powered by AI.
Write your eulogy in Woody Allen style.
Prepare the minister speech as if he was Neil deGrasse Tyson.
Make the plans for a funeral wake like Paris Hilton would.
Yes. We can help you with this and more.
Have the best funeral of the year. With Empathy.”
I hear you. You want to get better at using GPT-4 and LLaMA and MidJourney and Stable Diffusion and XYZ for your own job. I received a lot of requests about this.
Fine.
I’m adding a new section to the Splendid Edition called Prompting.
There are two reasons why it’s called this way.
The first reason is that there’s little to no engineering in the “Prompt Engineering” you see on social media.
The term engineering is derived from the Latin ingenium, meaning “cleverness” and ingeniare, meaning “to contrive, devise.”
It’s not that prompt engineering doesn’t exist. It does, but it’s confined within the sharp virtual borders