
- What’s AI Doing for Companies Like Mine?
Learn what Estes Express Lines, the California Department of Forestry and Fire Protection, and JLL are doing with AI. - A Chart to Look Smart
McKinsey offered a TCO calculator to CIOs and CTOs who want to embrace generative AI. Something is not right. - What Can AI Do for Me?
How I used generative AI to power the new Breaking AI News section of this newsletter. You can do the same in your company. - The Tools of the Trade
A new, uber-complicated, maximum-friction, automation workflow to generate images with ComfyUI and SDXL.
As I mentioned in the intro of this week’s Free Edition, starting this week, the Splendid Edition gains exclusive access to the A Chart to Look Smart section.
This section will continue to be about reviewing high-value industry trends, financial analysis, and academic research focused on the business adoption of AI. Going forward, there will be even more emphasis on hard-to-discover academic research that might give your organization an edge.
Also, the section Screwed Industries changes name to What’s AI Doing for Companies Like Mine?
Let me know what you think about these changes.
Alessandro
What we talk about here is not about what it could be, but about what is happening today.
Every organization adopting AI that is mentioned in this section is recorded in the AI Adoption Tracker.
In the Logistics industry, Estes Express Lines is using AI to analyze road conditions for truck drivers.
Angus Loten, reporting for The Wall Street Journal:
Todd Florence, CIO of Estes Express Lines, a Richmond, Va.-based shipper, said the company is using a similar system to operate AI-enabled vision software in truck-mounted cameras designed to alert drivers to road hazards ahead. “We no longer have to wait for data to be streamed to a centralized service, either in the cloud or our own data center,” he said. “This improves safety overall by nudging people in the moment.”
…
Florence said the company’s early investments in AI-powered computer-vision systems relied on centralized, cloud-based processing. Reducing the costs of added data storage and computing resources for AI tools was a key factor in switching to a distributed system, Florence said, adding that the bigger impact has been improved performance.
The article specifically focuses on business cases where the companies are running some of these AI models on the so-called “edge” rather than in the cloud. That’s a fancy way to say “on the device”, which in this case means on the truck itself.
The AI community has started increasing the efficiency of existing models and we are seeing more and more of them able to run on consumer hardware and, in some cases, on mobile devices. But, overall, we have not yet entered the optimization phase of modern AI.
Thanks to the increasingly powerful devices we are developing, and the upcoming efficiency improvements, you should expect to see a myriad of specialized AI models running in every device around us. From toasters to trucks.
In the Preservation industry, the California Department of Forestry and Fire Protection is using AI to detect early signs of wildfires.
Thomas Fuller, reporting for the New York Times:
For years, firefighters in California have relied on a vast network of more than 1,000 mountaintop cameras to detect wildfires. Operators have stared into computer screens around the clock looking for wisps of smoke.
This summer, with wildfire season well underway, California’s main firefighting agency is trying a new approach: training an artificial intelligence program to do the work.
…
Officials involved in the pilot program say they are happy with early results. Around 40 percent of the time, the artificial intelligence software was able to alert firefighters of the presence of smoke before dispatch centers received 911 calls.“It has absolutely improved response times,” said Phillip SeLegue, the staff chief of intelligence for the California Department of Forestry and Fire Protection, the state’s main firefighting agency better known as Cal Fire. In about two dozen cases, Mr. SeLegue said, the A.I. identified fires that the agency never received 911 calls for. The fires were extinguished when they were still small and manageable.
…
The A.I. pilot program, which began in late June and covered six of Cal Fire’s command centers, will be rolled out to all 21 command centers starting in September.But the program’s apparent success comes with caveats. The system can detect fires only visible to the cameras. And at this stage, humans are still needed to make sure the A.I. program is properly identifying smoke.
Engineers for the company that created the software, DigitalPath, based in Chico, Calif., are monitoring the system day and night, and manually vetting every incident that the A.I. identifies as fire.
…
The A.I. system churns through billions of megapixels every minute, images generated by the network of cameras, which cover around 90 percent of California’s fire-prone territory, according to Dr. Driscoll.

Other technologies used by Cal Fire are described here: https://alertcalifornia.org.
In the Real Estate industry, the global real estate services company JLL, has launched its own GPT model to assist its employees and customers in the commercial real estate market.
Developed by JLL Technologies (JLLT), the technology division of JLL, the bespoke generative artificial intelligence (AI) model will be used by JLL’s 103,000+ workforce around the world to provide CRE insights to clients in a whole new way. JLL’s extensive in-house data will be supplemented with external CRE sources, and the company plans to offer made-to-order solutions to clients later this year.
…
For example, JLL’s facility managers will be able to use generative AI to transform standard real estate space utilization and portfolio optimization dashboards into dynamic conversations that lead to more actionable decisions. Additionally, JLL consulting experts can provide comprehensive workplace planning advice to clients more quickly by combining qualitative information they gather through conversations with JLL GPT.
…
JLL has already deployed AI technology to improve building efficiencies, generate 3D leasing visualizations, calculate sustainability risks and power investment leads. For example, one in five of all JLL Capital Markets opportunities globally was enabled by the company’s AI-powered platform in the first quarter of 2023.
As fine-tuning becomes easier and easier (read the next section), everybody will attempt to offer a GPT model.
You won’t believe that people would fall for it, but they do. Boy, they do.
So this is a section dedicated to making me popular.
Last month, McKinsey issued a series of recommendations for CIOs and CTOs looking to implement an infrastructure to train or fine-tune AI models.
The only part that is truly interesting is their estimates for the total cost of ownership, depending on what approach you want to take.
For example, if you only use an off-the-shelf generative AI model with a layer of prompt engineering built on top of it, this is the TCO estimate:

If, instead, you intend to fine-tune a model with proprietary data, their TCO estimate becomes:

Finally, if you want to train a foundation model from scratch, your TCO becomes:

On multiple occasions, in the last few issues of Synthetic Work, I have recommended growing an in-house AI team and developing the skills to fine-tune models. This will be an essential skill for any organization that wants to stay competitive in the next decade.
At the same time, I have passionately discouraged the idea of training foundation models from scratch. There’s just economic benefit in doing so, for many reasons that I won’t repeat again.
With this in mind, you should be cautious with these TCO estimates. It’s hard to say what are the assumptions without a chance to review the model, but here are some things you might want to consider:
- Prompt engineering is real, as the readers of the Splendid Edition know, but it’s temporary. Not just because these AI models will eventually get so good at understanding our intent that skillfully crafted prompts will become less and less necessary, but also because AI technology providers are already working to simplify the effort necessary to engineer prompts for large organizations.As a first step, a few weeks ago, OpenAI introduced the capability to define a system prompt (which they called Custom Instructions). We’ll put it to good use in a future Splendid Edition.You should expect OpenAI and competitors to offer soon enterprise subscriptions to their AI models, where companies will be able to define system prompts that will be applied to every interaction with every employee. And that will be used for a myriad of tasks, from enforcing a specific style guide to the output of the model, to moderating content following specific corporate policies.The cost of implementing the scaffolding necessary for your system prompts will drop precipitously.
- The idea that a company will stick with the same model for a while, only having to maintain the integration with the AI technology provider APIs is completely unrealistic.Imagine a customer that built on top of GPT-2 or even GPT-3 just last year. GPT-4 is so unbelievably better. Sticking with a previous-generation model would seriously impact the capability of a company to compete. For McKinsey’s assumptions to work, you should assume that GPT-5, GPT-6, etc. will only introduce incremental improvements.Instead, you should expect to replace your AI models at least once a year to remain competitive.
- Data collection and preparation is the most complex task in any AI project and its cost is often underestimated.I’ve seen first-hand how difficult is to collect data in a large organization, and judge the quality of that data through subject matter experts. Technicalities, organization complexity, legal and compliance issues, political fights, lack of time from the data owners, make this task vastly more expensive than most companies expect.A team of machine learning engineers and data engineers doesn’t work in a vacuum and they have no power to address most of the issues I list above.Moreover, if you are a “shaper”, to use McKinsey terminology, competition will push companies to find more and more proprietary data to train their models. This will increase not just the scale to manage, but also the complexity in retrieval.
- The cost of fine-tuning will drop precipitously.Earlier this week, OpenAI announced its first mechanism to fine-tune GPT-3.5 (another thing that we’ll test in a near future). Just like for the scaffolding necessary for prompt engineering, the costs associated with the mechanics of fine-tuning will go down.The compute cost associated with fine-tuning will drop as soon as technology providers understand how to use the new Nvidia GH200 GPUs, developing models that take full advantage of it.The ongoing compute capacity shortage will be relieved in the next 12-18 months: according to the Financial Times, Nvidia will at least triple the production of its H100 AI GPUs in 2024 shipping between 1.5mn and 2mn H100s in 2024, compared to the 500,000 expected this year.We are entering a model optimization phase that will significantly boost the performance of open access/open source models, including their fine-tuning.
Another thing I mentioned in this week’s Free Edition is the introduction of the Breaking AI News section. If you haven’t checked it out yet, head to https://synthetic.work/news and take a look. Browse a little bit, to understand what information is available there and then come back.
Done? Let’s talk about how I created this and how you can do the same for your organization about any topic you want.
The (beloved) tools I used to implement this are:
- WordPress
- Uncanny Automator
- OpenAI GPT-4 and Dall-E
I used WordPress for over 15 years. It is, together with a very specific set of plug-ins, my irreplaceable content management system. There’s nothing on the market that comes close to it in terms of flexibility and ease of use.
One of these plug-ins is Uncanny Automator, which we already mentioned in Issue #5 – The Perpetual Garbage Generator.
In turn, Uncanny Automator integrates with GPT-4 and Dall-E in wonderful ways. For that integration to work, we need API access to OpenAI models.
With these building blocks, any Line of Business or team, inside any organization, without any technical expertise, can create a content generation machine that would have cost enormous effort and money just one year ago.
In the example below, we’ll use these building blocks to strip away the hype from the news and generate a telegraphic summary of the content. But imagine that this approach can be used to summarize and publish long industry analysis reports, earning calls, meeting minutes, and so on.
How to automatically summarize and publish content
Let’s assume that you have installed and configured WordPress and Uncanny Automator (you’ll need the Pro version to do what follows at scale).
You can create a new recipe Uncanny Automator’s recipe that looks like this:
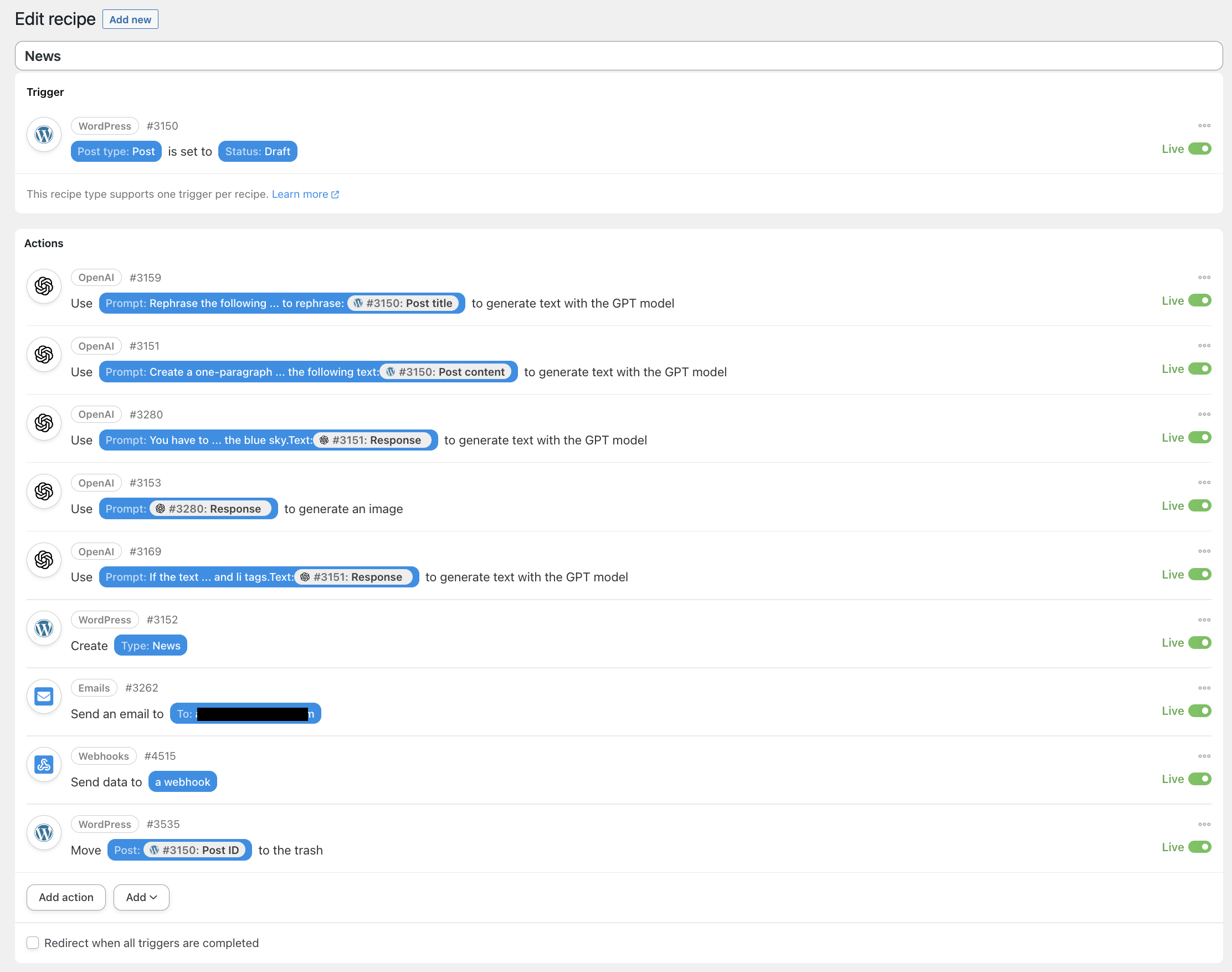
The first thing we must do is ingest the data that we want to summarize and save it in a draft WordPress post. We can ingest data via email, RSS, an entry in a Google Sheet or Airtable, etc.
Uncanny Automator offers you a variety of ways to do that, thanks to its many integrations, but we can use any other way we like. Even manual entry (which sort of defeats the purpose of this whole exercise).
We won’t get into the details of this phase for a number of reasons.
The critical part is setting the draft status as it’s that status that informs Uncanny Automator that it’s time to do its magic.
Once a new draft is created, the first step of the workflow is executed. This focuses on rewriting the original title by stripping away the hype:
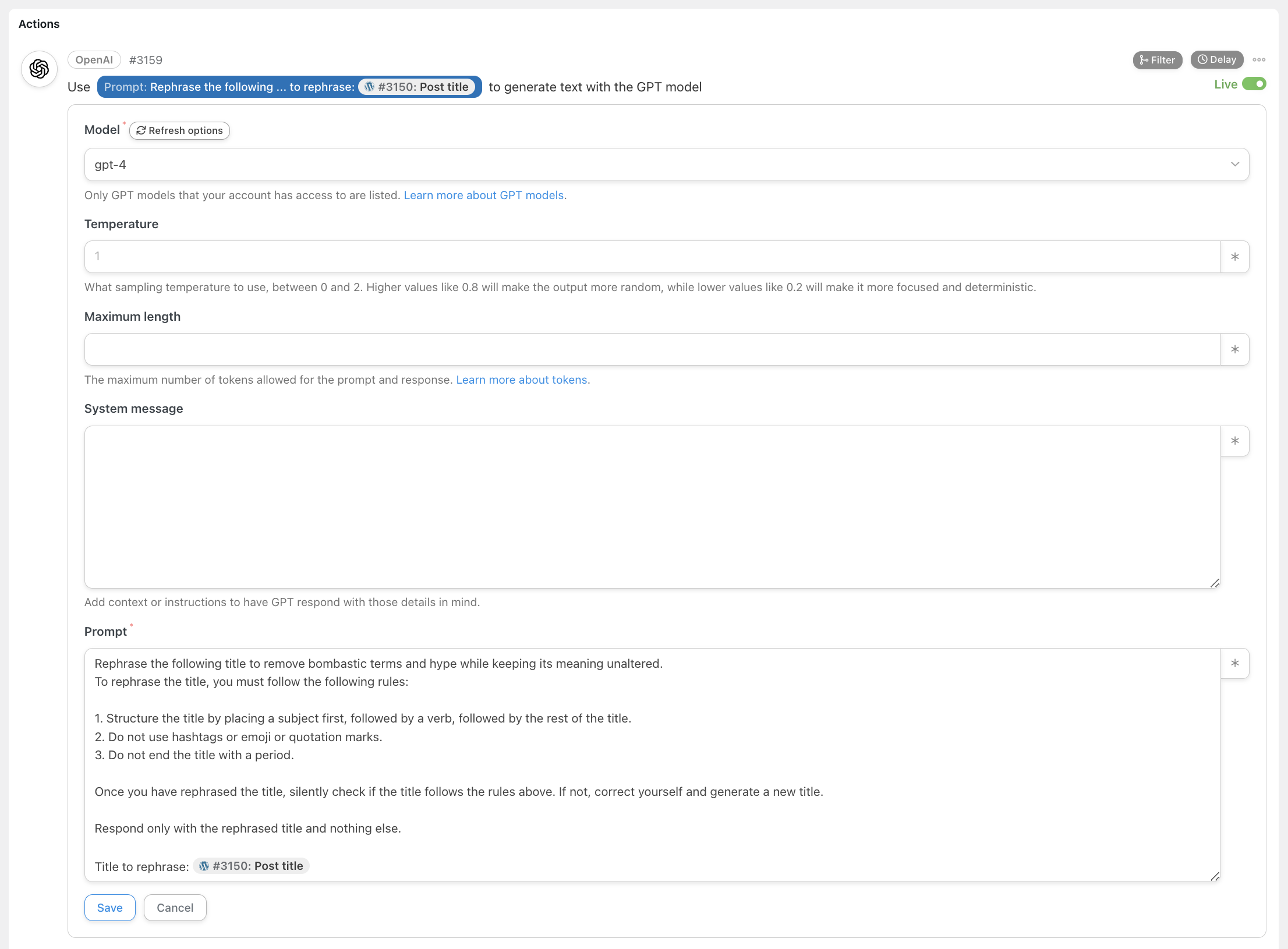
From now on, everything we have learned and saved in the How to Prompt section of Synthetic Work over these first 6 months comes into play.
For this particular prompt, notice that I asked the AI to silently double-check if it followed the rules that it should have followed in rewriting the title.
Remember that the generation process doesn’t automatically imply verification of the output for accuracy, consistency, etc. like it happens for humans. We must explicitly ask the model to do that.
Also notice that, while Uncanny Automator offers you the possibility to interrogate any model OpenAI offers via its API, I exclusively use GPT-4. While much cheaper, GPT-3.5-Turbo is far from mature enough for this task.
The next step is about summarizing the original content of the news:
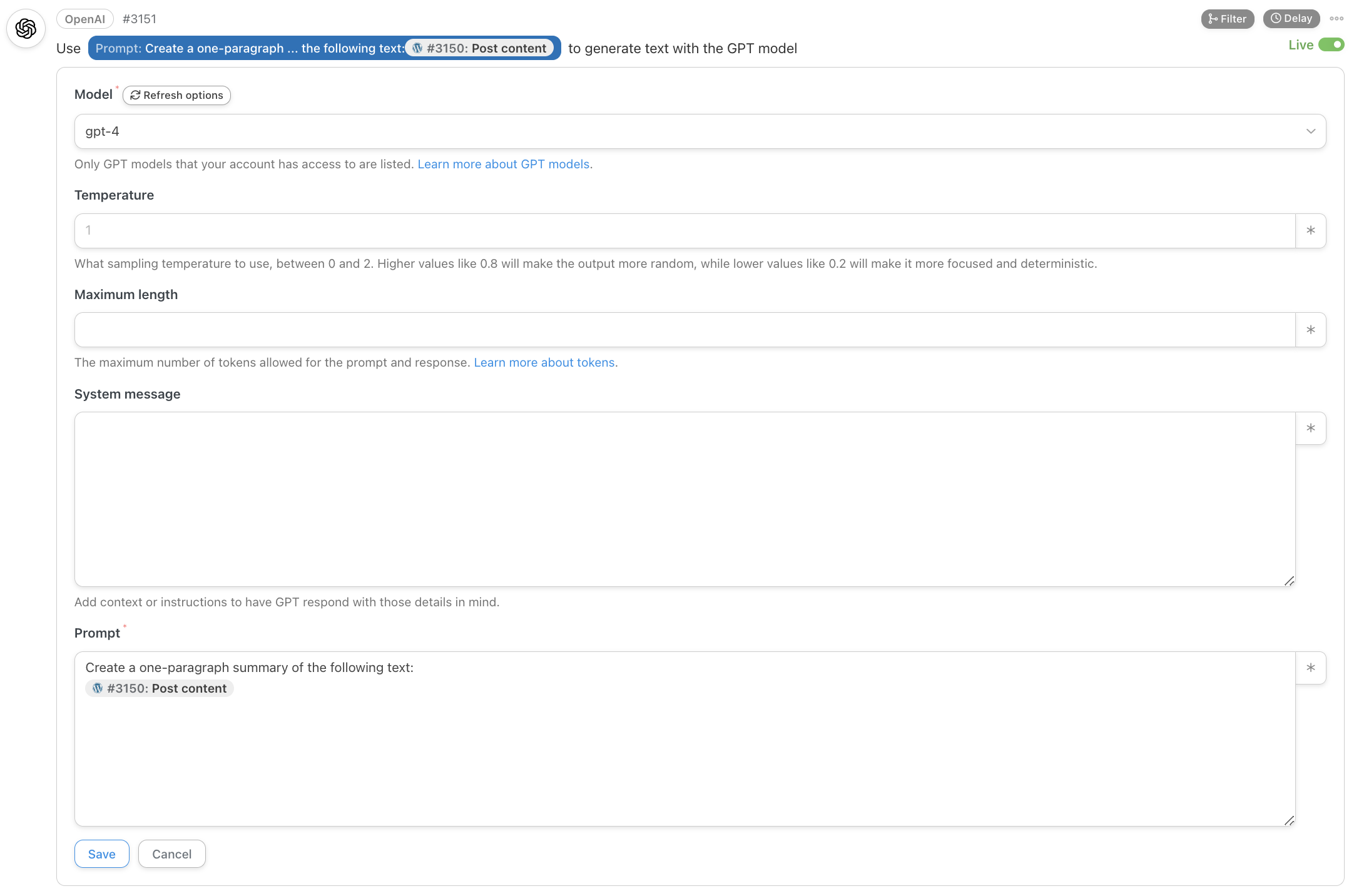
As you can see, I did nothing special here. I could modify this prompt to generate two paragraphs instead of one, summarize in line with a certain type of content (e.g., sport), mimic the style of a specific author (assuming his/her material was in the training set of GPT-4), attempt to copy the approach of certain publications like Reuters or Bloomberg, etc.
The sky is the limit but, for now, the ultra-basic prompt I’m using is enough.
Now we want to generate an image associated with the news. This is the most complex part of the workflow, requiring two steps.
First, we ask GPT-4 to generate a description of the image we want to create:
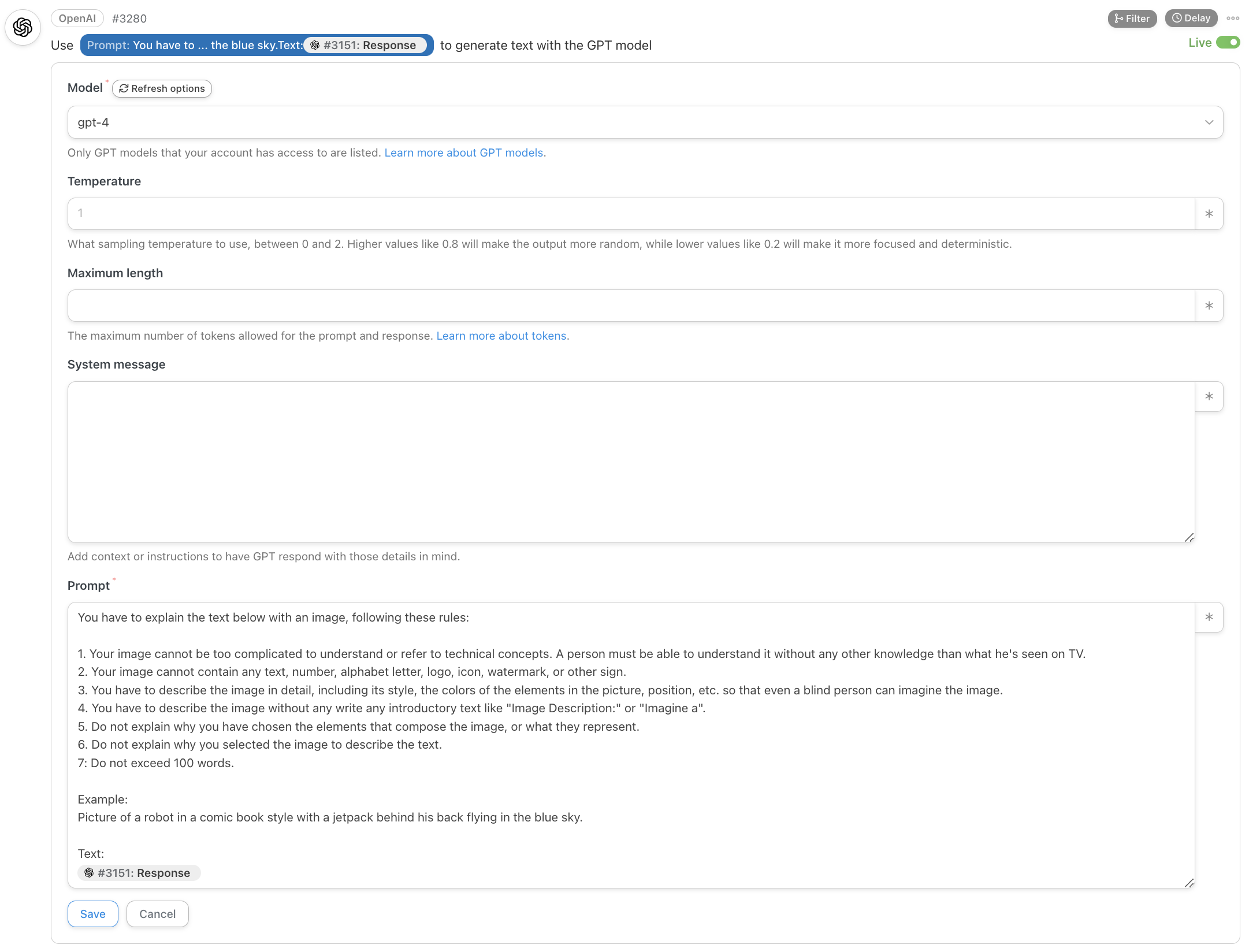
If you read Issue #25 – Hypnosis for Business People, where I show a technique to generate images for your business presentations, you’ll notice that this is a completely different approach.
Also notice that I’m using a prompting technique we have encountered many times: Lead by Example.
The more examples you’ll provide to GPT-4, the better.
Once we have the description, we’ll use it as a prompt for the text2image (t2i) OpenAI model called Dall-E:
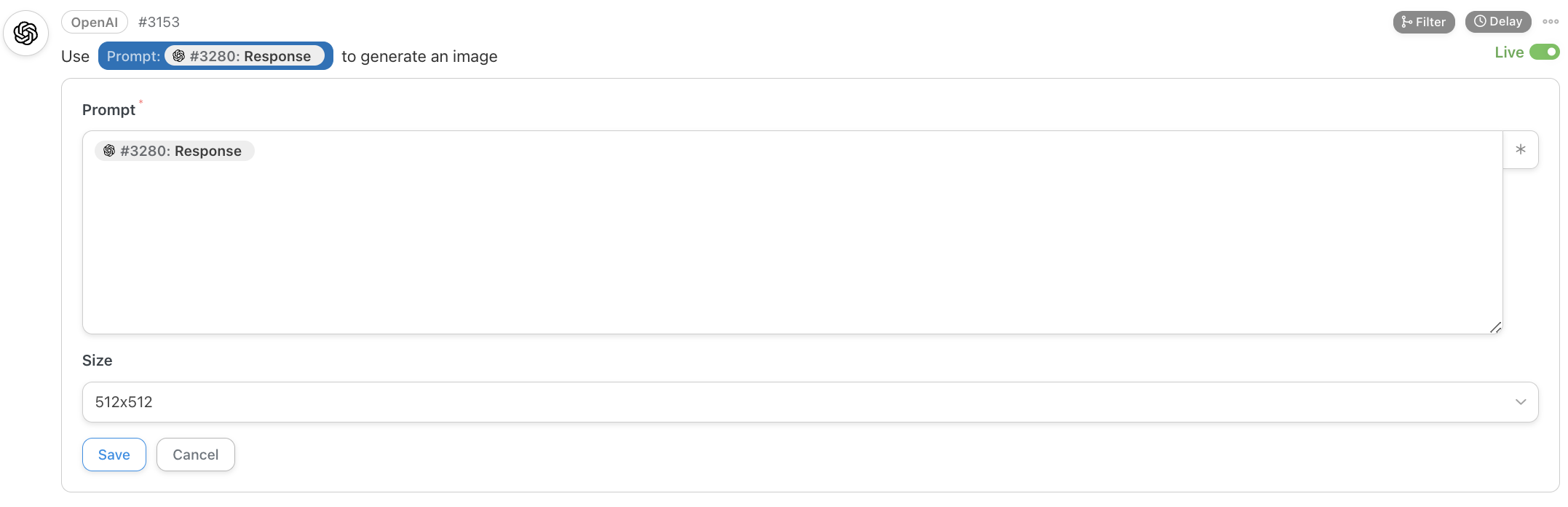
As you probably read in the comparison table I created for Issue #25 – Hypnosis for Business People, Dall-E is the least performing t2i model available today, long surpassed by Midjourney and Stable Diffusion XL (SDXL).
Also, as we speak, OpenAI still only offers the generation of square images via its API.
Both things are about to change. I heard from one of the employees that they are working on an interim version of Dall-E, call it 2.5 if you like, that will be able to generate much better pictures and in landscape and portrait mode.
So, the cover image of each breaking news will improve in the future.
I could use Stability AI APIs, to generate images with SDXL, but Uncanny Automator has a very convenient integration with OpenAI and I prefer to leverage that for now.
At this point, we have everything to publish the hype-free telegraphic breaking AI news I promised you. But generative AI opens a world of possibilities and I wanted to do something extra, something special:
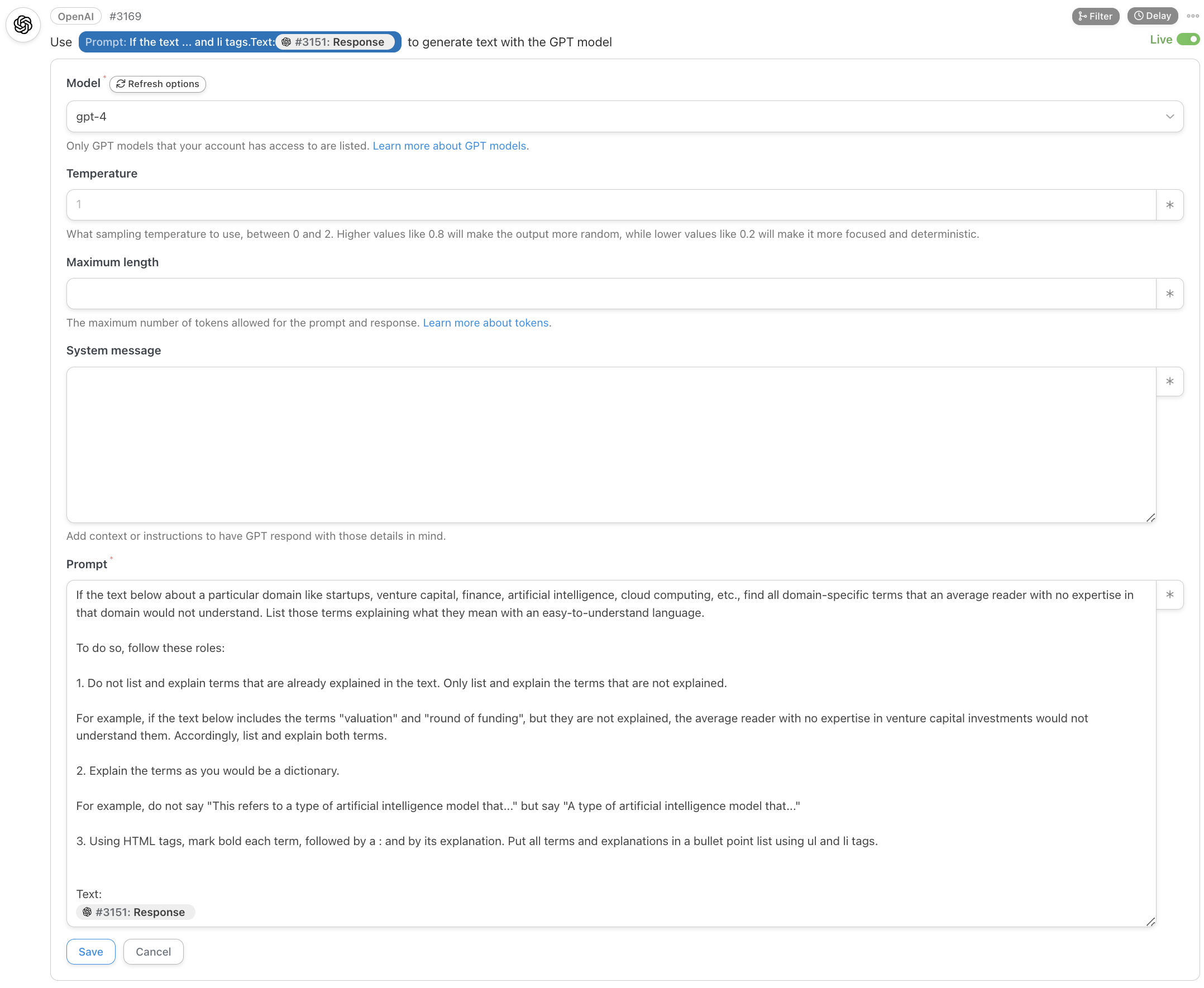
Throughout my career, simplifying complex concepts for a non-technical audience has been a top priority.
Democratizing access to knowledge by removing domain-specific jargon is critical to generating more winning ideas. That’s because the people who understand a problem best often are not the ones who can solve it.
So, using GPT-4 to explain the most obscure terms in each breaking news makes me smile a lot.
Unfortunately, this part of the workflow is the least robust: often, GPT-4 explains things that are trivial or already explained in the article. But a more refined prompt could lead to better results. I need more experimentation.
OK.
Finally, we can publish the news: we have a cover image, a hype-free title, a one-paragraph summary, and an explanation of the most obscure terms in the news.
We take all these ingredients and put them in a new post, which will be published automatically. We don’t modify the initial draft, which contains the original material used to generate the news.
Once the post is published, we generate the relevant alerts: one for me, via email, to confirm that there’s a new breaking news to double-check (especially for the explainer part), and one for you, via Discord, as I explained in the intro of the Free Edition.
At the very end of the workflow, we delete the original draft as we don’t need it anymore.
There.
Now, you too are ready to build a Perpetual Garbage Generator for your organization.
I’d like to close by reminding you that “with great power comes great responsibility”, but then I think about Deadpool. Forget it.
Last week, in Issue #25 – Hypnosis for Business People, we saw a variety of text-2-image (t2i) AI systems to generate images for our boring corporate presentations.
Among other things, I showed how I use a particularly complex (and frustrating) user interface called ComfyUI to automate the generation of the two covers of Synthetic Work every week.
Some of you reached out to have more information about the ComfyUI workflow I showed, which I heavily modified in these seven days.
So, I decided to publish it in full here: https://perilli.com/ai/comfyui/.
As you’ll read on the page above, this workflow remains a work-in-progress, but it already contains everything necessary to generate images on your local computer with the SDXL 1.0 diffusion model and understand the power of automated image generation.