
- What’s AI Doing for Companies Like Mine?
- Learn what BBC, The Washington Post, and Thomson Reuters are doing with AI.
- A Chart to Look Smart
- What can we do by training an AI with the lifetime of the most intelligent person on Earth, educated to be a business/science/engineering/etc. leader, and recorded as he/she goes through life and is successful?
- What Can AI Do for Me?
- Here’s how the new GPT-4V might transform customer support.
- The Tools of the Trade
- Finally, a tool I can recommend to organize ChatGPT chats.
What we talk about here is not about what it could be, but about what is happening today.
Every organization adopting AI that is mentioned in this section is recorded in the AI Adoption Tracker.
In the Publishing industry, the BBC is testing generative AI for newsroom tasks, while making it clear that they want to be paid by AI providers for scraping their content.
Rhodri Talfan Davies, BBC’s Director of Nation, on the corporate blog:
We believe Gen AI could provide a significant opportunity for the BBC to deepen and amplify our mission, enabling us to deliver more value to our audiences and to society. It also has the potential to help our teams to work more effectively and efficiently across a broad range of areas including production workflows and our back-office.
Alongside these opportunities, it is already clear that Gen AI is likely to introduce new and significant risks if not harnessed properly. These include ethical issues, legal and copyright challenges, and significant risks around misinformation and bias.
…
With all this in mind, today we’re outlining three principles that will shape our approach to working with Gen AI:
- We will always act in the best interests of the public – We will explore how we can harness Generative AI to strengthen our public mission and deliver greater value to audiences. At the same time, we will seek to mitigate the challenges Generative AI may create, including trust in media, protection of copyright and content discovery. We will also seek to work with the tech industry, media partners and regulators to champion safety and transparency in the development of Gen AI and protection against social harms.
- We will always prioritise talent and creativity – No technology can replicate or replace human creativity. We will always prioritise and prize authentic, human storytelling by reporters, writers and broadcasters who are the best in their fields. We will work with them to explore how they could use Generative AI to help them push new boundaries. Creators and suppliers play a vital role in our industry. The BBC will always consider the rights of artists and rights holders when using Generative AI.
- We will be open and transparent – Trust is the foundation of the BBC’s relationship with audiences. Our leaders will always remain accountable to the public for all content and services produced and published by the BBC. We will be transparent and clear with audiences when Generative AI output features in our content and services. Human oversight will be an important step in the publication of Generative AI content and we will never rely solely on AI-generated research in our output.
In the next few months, we will start a number of projects that explore the use of Gen AI in both what we make and how we work – taking a targeted approach in order to better understand both the opportunities and risks. These projects will assess how Gen AI could potentially support, complement or even transform BBC activity across a range of fields, including journalism research and production, content discovery and archive, and personalised experiences.
At the same time, we are taking steps to safeguard the interests of Licence Fee payers as this new technology evolves. For example, we do not believe the current ‘scraping’ of BBC data without our permission in order to train Gen AI models is in the public interest and we want to agree a more structured and sustainable approach with technology companies. That’s why we have taken steps to prevent web crawlers like those from Open AI and Common Crawl from accessing BBC websites.
We are also looking at how Gen AI may influence the media industry more broadly. For example, how the inclusion of Gen AI in search engines could impact how traffic flows to websites, or how the use of Gen AI by others could lead to greater disinformation.
In the Publishing industry, The Washington Post uses AI to generate short news articles from structured data, such as sports scores and earnings reports.
Lucia Moses, reporting for Digiday:
It’s been a year since The Washington Post started using its homegrown artificial intelligence technology, Heliograf, to spit out around 300 short reports and alerts on the Rio Olympics. Since then, it’s used Heliograf to cover congressional and gubernatorial races on Election Day and D.C.-area high school football games.
…
In its first year, the Post has produced around 850 articles using Heliograf. That included 500 articles around the election that generated more than 500,000 clicks — not a ton in the scheme of things, but most of these were stories the Post wasn’t going to dedicate staff to anyway. For the 2012 election, for example, the Post did just 15 percent of what it generated in 2016.
…
Media outlets using AI say it’s meant to enable journalists to do more high-value work, not take their jobs. The AP estimated that it’s freed up 20 percent of reporters’ time spent covering corporate earnings and that AI is also moving the needle on accuracy.
…
During the election, it used Heliograf to alert the newsroom when election results started trending in an unexpected direction, giving reporters lead time to thoroughly cover the news. Gilbert wants Heliograf to play a more ambitious role in the next election. He also sees the potential for Heliograf to do legwork for reporters in other ways, like spotting trends in financial and other big data sets. “We think we can help people find interesting stories,” he said. Heliograf also can be deployed to update ongoing stories like weather events in real time, providing a service to readers.
…
Right now, the Post can count the stories and pageviews that Heliograf generated. Quantifying its impact on how much time it gives reporters to do other work and the value of that work is harder. It’s also hard to quantify how much engagement, ad revenue and subscriptions can be attributed to those robo-reported stories. (On the resource side, now that it’s built, Heliograf has about five people dedicated to it, not including editors that it borrows to help figure out how to apply it.)
This article was published in 2017. The Washington Post started using AI to generate content in 2016, well before OpenAI introduced the incredible level of sophistication we are seeing with the GPT-4 family of models.
As you can tell by other stories in this Splendid Edition and by the LSE report shared in this week’s Free Edition, the adoption of AI in the Publishing industry is very uneven and some news organizations are well ahead of others.
It will be like this across all industries: some companies will understand much earlier than others the enormous opportunity that AI represents and will pull far ahead of the competition.
Is your company ahead of your competitors?
In the Publishing industry, Thomson Reuters is using generative AI for a range of creative use cases, from invoice review to legal research to newsworthiness prediction.
From their timeline page about AI adoption:
Using machine learning classification techniques to predict if an invoice narrative violates specific billing guidelines, we launched a feature to detect block billing on invoices and invoice items describing non-reimbursable work such as travel, or internal communication.
…
State-of-the-art AI system designed to find the answers to free-form questions in Practical Law. It searches content-based on complex questions, as opposed to keyword queries
…
Onvio introduced a new AI-based capability that helps customers with the tedious steps involved in the classification of accounts for tax purposes.
…
A recent example is the UK Judicial Cases Editorial Treatment Process, which predicts the importance of an incoming case, based on properties like court name, subject area, keywords, and even level of anonymization required, if any.The automated process leverages AI in order to queue the work for editors and to help ensure that the most important cases are processed first by our editorial team.
Thomson Reuters does much more than this with AI, summarizing and publishing news articles being a core part of their business.
The irony is that the company is very unhappy about other organizations using AI to summarize their content.
Blake Brittain, writing for Reuters:
A jury must decide the outcome of a lawsuit by information services company Thomson Reuters accusing Ross Intelligence of unlawfully copying content from its legal-research platform Westlaw to train a competing artificial intelligence-based platform, a Delaware federal judge said on Monday.
…
Thomson Reuters’ 2020 lawsuit accused legal research company Ross Intelligence of copying Westlaw’s “headnotes,” which summarize points of law in court opinions. Thomson Reuters accused Ross of misusing thousands of the headnotes to train its AI-based legal search engine.Ross said it shut down its platform in January 2021, citing the costs of the “spurious” litigation. Reuters could not establish if it did so.
…
Ross argued in part that it made fair use of the Westlaw material, raising what could be a pivotal question for legal disputes over generative AI training.Ross said that the Headnotes material was used as a “means to locate judicial opinions,” and that the company did not compete in the market for the materials themselves. Thomson Reuters responded that Ross copied the materials to build a direct Westlaw competitor.
…
“Here, we run into a hotly debated question,” Bibas said. “Is it in the public benefit to allow AI to be trained with copyrighted material?”
You won’t believe that people would fall for it, but they do. Boy, they do.
So this is a section dedicated to making me popular.
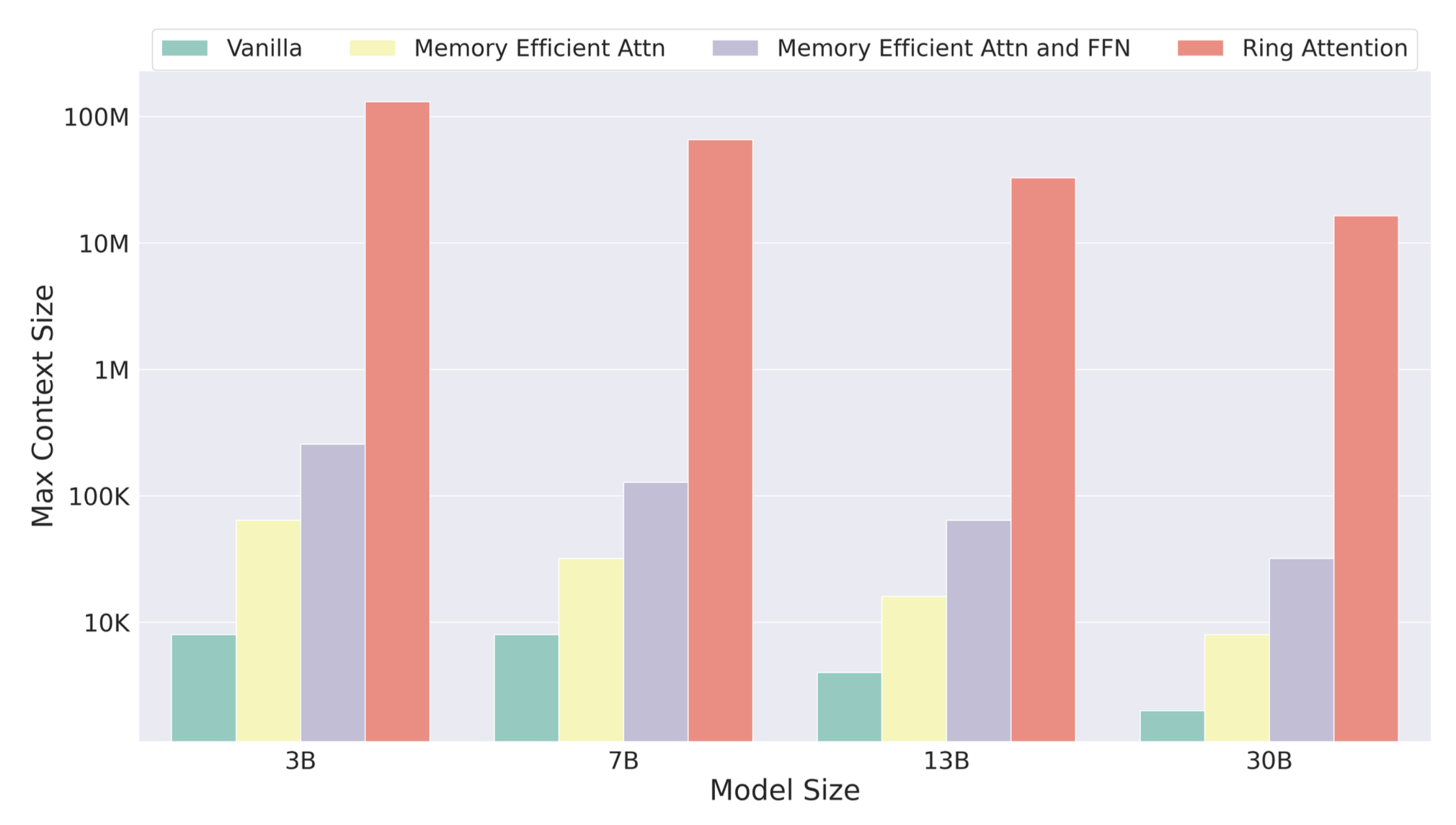
This will possibly become the most important chart of 2023. If the research is right, a new technique to expand the context window of large language models will unlock wild scenarios, even for today’s bleeding-edge AI.
If you’ve read Synthetic Work since the beginning, you know that this newsletter closely tracks the progress of large language models in terms of context window, the short-term memory of an AI agent that allows it to remember things said during a conversation and stay consistent for long periods of time.
If you’ve read Synthetic Work since the beginning, you also know that, in a now-deleted interview, OpenAI’s CEO suggested that we might see a GPT-4 model with a context window of 1 million tokens by the end of 2023.
Which would enable significantly more use cases than the ones possible today with the 8,000 or 32,000 token variants of GPT-4, or the 100,000 token variant of Claude, that we have today.
An AI agent able to remember and elaborate on 750,000 words (100 words are approximately equal to 75 tokens) would be able to lead hours of conversation with therapy patients or elders in need of care, for example. It would be able to respect and enforce hugely complex rules like the ones in the legal system. It would be able to write multi-volume books or scripts for multi-year TV series.
Hence the question: why would we need a context window bigger than 1 million tokens?
Until now, there was little reason to contemplate the answer as the AI community couldn’t see a path forward to expand the context window beyond 1 million tokens.
But this new Ring Attention technique might change everything.
From the paper, titled Ring Attention with Blockwise Transformers for Near-Infinite Context:
the memory demands imposed by Transformers limit their ability to handle long sequences, thereby creating challenges for tasks involving extended sequences or long-term dependencies. We present a distinct approach, Ring Attention, which leverages blockwise computation of self-attention to distribute long sequences across multiple devices while concurrently overlapping the communication of key-value blocks with the computation of blockwise attention. By processing longer input sequences while maintaining memory efficiency, Ring Attention enables training and inference of sequences that are device count times longer than those of prior memory-efficient Transformers, effectively eliminating the memory constraints imposed by individual devices.
…
Our Ring Attention model consistently surpasses baselines, delivering superior scalability across diverse hardware setups. For example, with 32 A100 GPUs, we achieve over 32 million tokens in context size, a significant improvement over baselines. Furthermore, when utilizing larger accelerators like TPUv4-512, Ring Attention enables a 512x increase in context size, allows training sequences of over 100 million tokens.
In other words, researchers have found a way to spread the context window of a large language model across multiple computers, surpassing the limits imposed by the resources physically present on a single device.
The more computers you cluster together, the bigger the context window you can create, reaching astonishing numbers like 100 million tokens with extremely expensive specialized hardware.
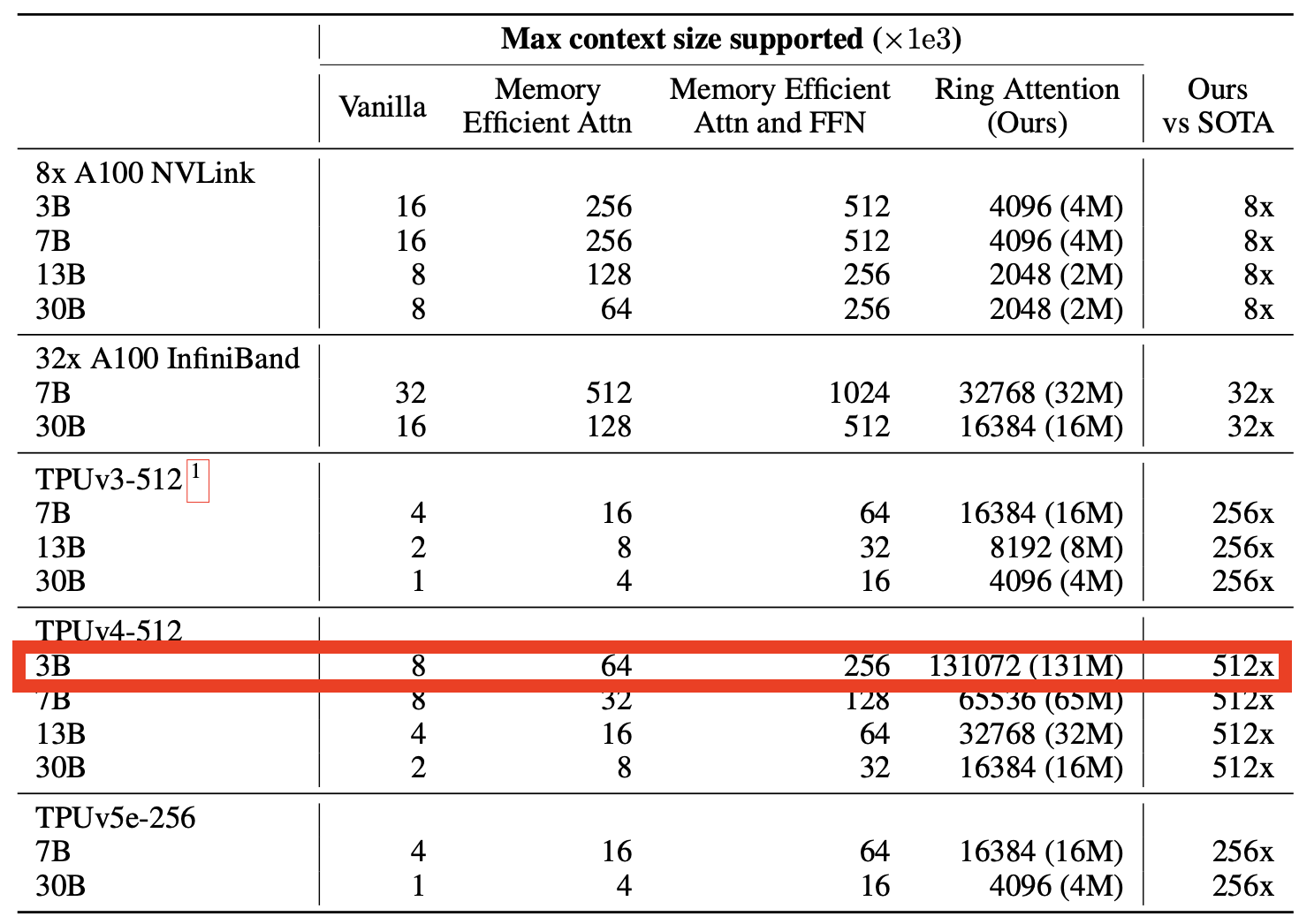
Which, in turn, means that, for now, and assuming this technique works as claimed, only the largest AI providers will be able to offer AI agents with this humongous short-term memory.
OK. Back to the question: why would we need a context window bigger than 1 million tokens?
To answer this critical question, we need a bit of context and then we need to go back to a previous Splendid Edition.
First, the context.
Assuming an 80-year lifespan, and an average of 16,000 spoken words per day (according to the most recent research published), you’d need 350 million tokens to record everything a single human says.
The total number of tokens is probably smaller, as we don’t say 16,000 words a day until adulthood. Perhaps significantly smaller, to the point that a context window of 100 million tokens is already sufficient to store an entire life.
Now, the previous Splendid Edition.
In Issue #31 – The AI Council, we saw how to use an exceptional new technology from Microsoft Research to turn multiple instances of GPT-4 into synthetic advisors, each specialized in a certain area of expertise, able to debate with each other about your business challenge until they reach a consensus and give you their best advice.
All of this is already extraordinary, but the quality of these synthetic advisors depends on the material used to train GPT-4.
As we said in Issue 31, we can assume that organizations like business schools like Harvard and professional services firms like McKinsey might tap into their vast archives of case studies and reports to fine-tune AI models in disciplines like business strategy and marketing.
But even that fine-tuning effort, while invaluable, is constrained by the small short-term memory of the AI model of choice. The context window.
Except that now, with Ring Attention, we might be able to count on a context window so big that it could store not just the aggregated best practices archived by Harvard or McKinsey, but the entire professional experience of a business leader.
And if we could do that, why would we try to capture the entire professional experience of a random business leader? Why not capture the entire professional experience of one of the best business leaders in the world?
In other words: what can we do by training an AI with the lifetime of the most intelligent person on Earth, educated to be a business/science/engineering/etc. leader, and recorded as he/she goes through life and is successful?
An AI provider might place multiple bets on multiple promising candidates, and then offer them a percentage of the profits should they be selected to become THE synthetic advisor for disciple X, Y, or Z.
That one champion, perhaps selected at the end of his/her career, might be offered to millions of companies and billions of users as a synthetic advisor, available 24/7 inside their smartphones, to discuss any business challenge and provide the best advice.
I’ll say in yet another way:
A 1M token context window will give AIs the ability to remember everything written in every book ever published about Warren Buffett.
A 100M token context window will give AI the ability to remember everything Warren Buffett has ever said, in every scenario, in every decision, and through every challenge.
We might have discovered the technology that allows the most capable humans on the planet to lift the rest of our species, unlocking a new era of prosperity and progress.
And that technology is not out of reach. It’s available and it can be put to use today by a well-funded startup or a public company.
That company could be yours.
If it’s not yours, but you know somebody who wants to build a company like that, please forward this Splendid Edition to them.
In Issue #32 – Hackathons For Fun and Profit, we read how the new GPT-4V model could be used to enable a wide range of new use cases across many industries.
But, to me, the most exciting use case is the capability for the AI to watch your computer desktop and intervene to fix your problem, or collaborate with you on something, or take over and finish your work while you are busy doing something else, or discover something about your routines that can be automated (a scenario I started seriously thinking about four years ago).
If you’ll allow it, the AI will see and interpret everything you are doing.
For example, the fact that you have to ask your AI agent (Copilot, Ghostwriter, etc.) to help when you find a bug or get stuck with something is only temporary. Now that AIs can “see” images, you have to assume that they will be able to observe your screen and proactively intervene when you are stuck. First, only within the context of a single application. Then, across every application on the screen. And you won’t need to say “I have a problem” anymore. It will be obvious to them.
This alone might drastically reduce the cost of support and the cost of training for any company in the world.
So, this “computer vision for desktops”, as I like to call it, is the area I’d like to explore today.
GPT-4 inference time, the time it takes for the AI to process a request and provide an answer, is still too long to process a live streaming of the screen. So, let’s see what it can do with a screenshot.
I’ll pick a relatively popular software that I use every day: Pixelmator Pro. I don’t expect its documentation to have been included in the training set for GPT-4, but there’s no way to know for sure.
I prefer Pixelmator Pro to Photoshop because I can’t tolerate the complexity of the Photoshop user interface and the absurd logic used to position the UI controls all over the place.
But even Pixelmator Pro is not as easy to use as it could be and, for a beginner, reviewing the documentation (or YouTube videos) is still mandatory in some cases.
Let’s say that I am in the following situation, trying to improve a less-than-spectacular picture taken during my visit to the Engineering Arts office in London, and I don’t remember the difference between Warp, Bump, Pinch and Twirl:
![]()
I could certainly describe my problem in a prompt to GPT-4, describing the context of Pixelmator Pro, but it’s long, and remember: the ultimate goal is to have the AI watch my screen and intervene when I am stuck in a frictionless way.
So, let’s see what happens if I use a screenshot of this situation as context and little else:
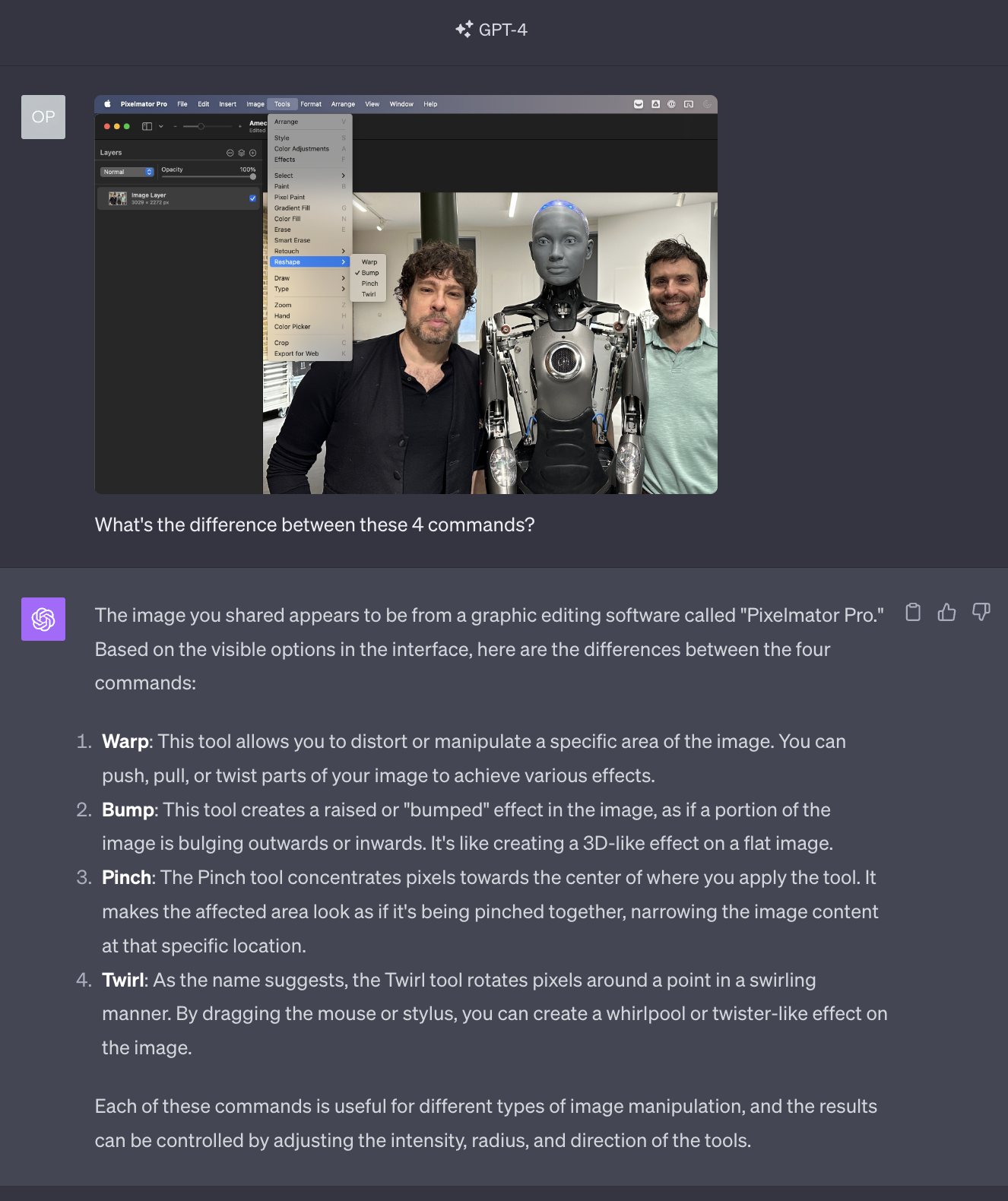
There.
This is one of those moments when you realize you are seeing the future. We are seeing the future here.
Let’s try something slightly harder, where describing the context in a written form would be so long to become impractical:

Notice how GPT-4V correctly focused on just four of the seven sliders in the screenshot.
How does it behave with even more complex visual elements, like a histogram?
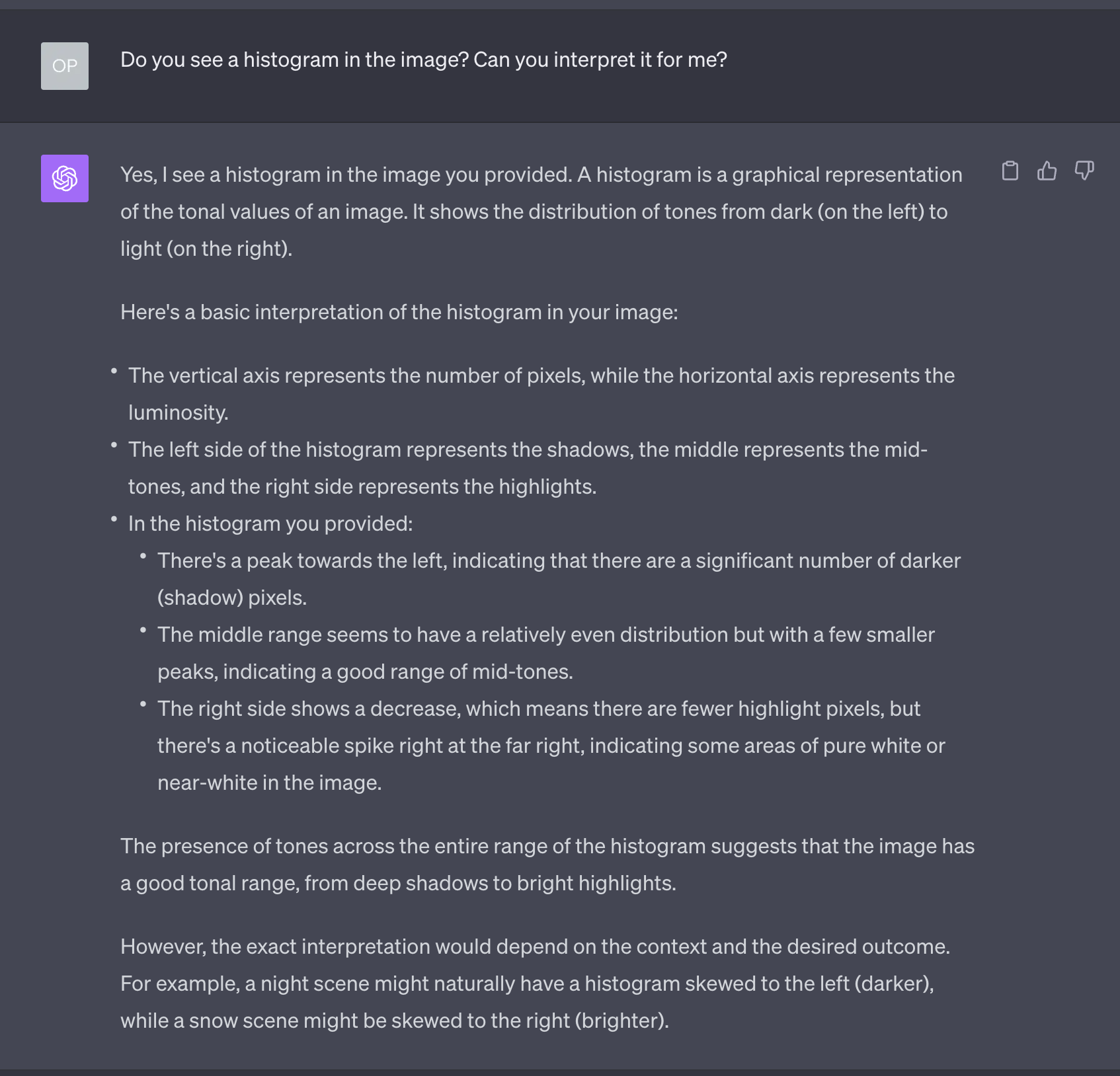
Pretty good, but it could have been more detailed. Let’s see if some encouragement helps:

ChatGPT had a momentary issue with the streaming of the answer and, upon regeneration, I didn’t get an answer as precise as this. But, by all means, this is a perfectly acceptable answer.
While all of this is beyond exceptional, be careful: the model seems to struggle with comparisons.
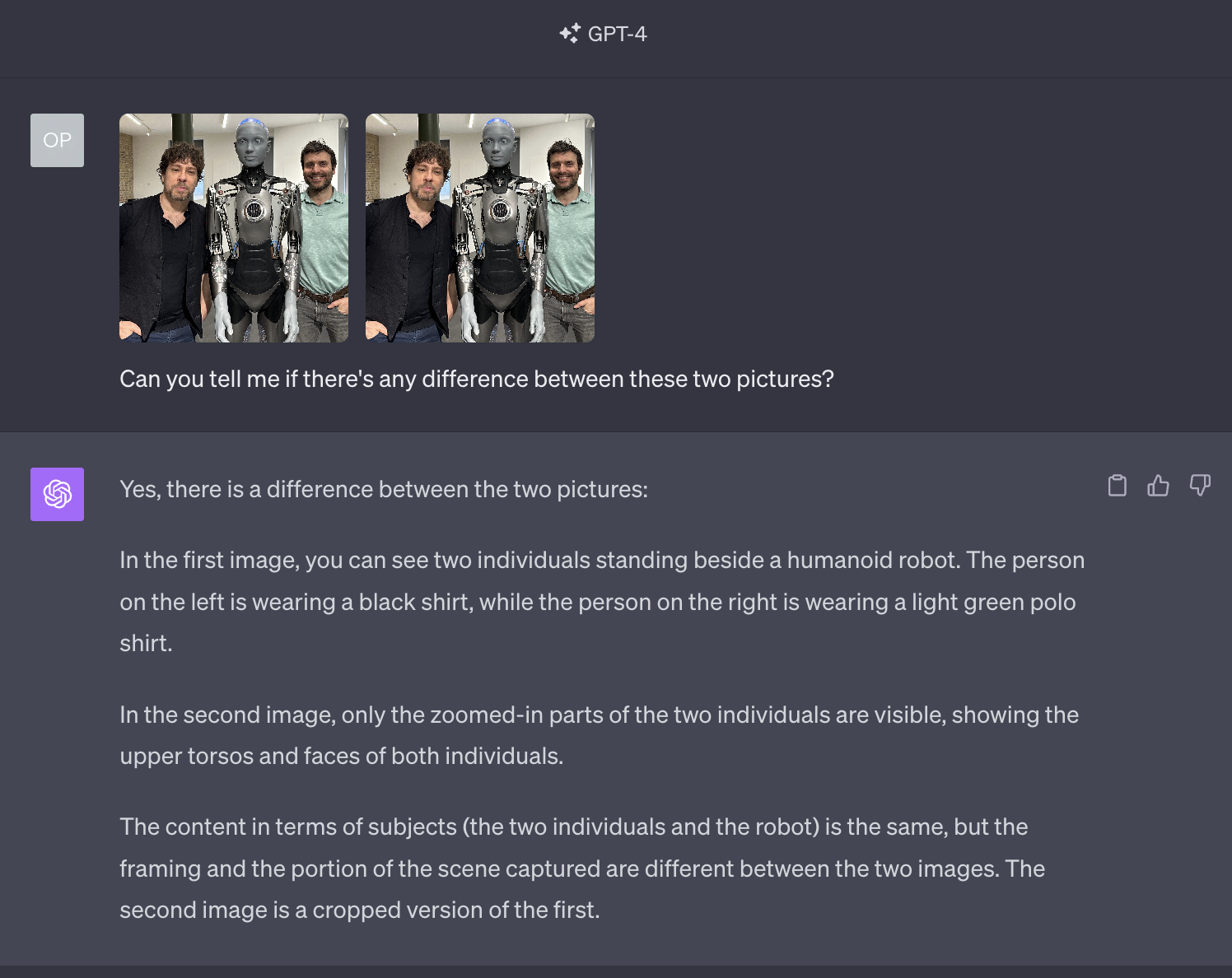
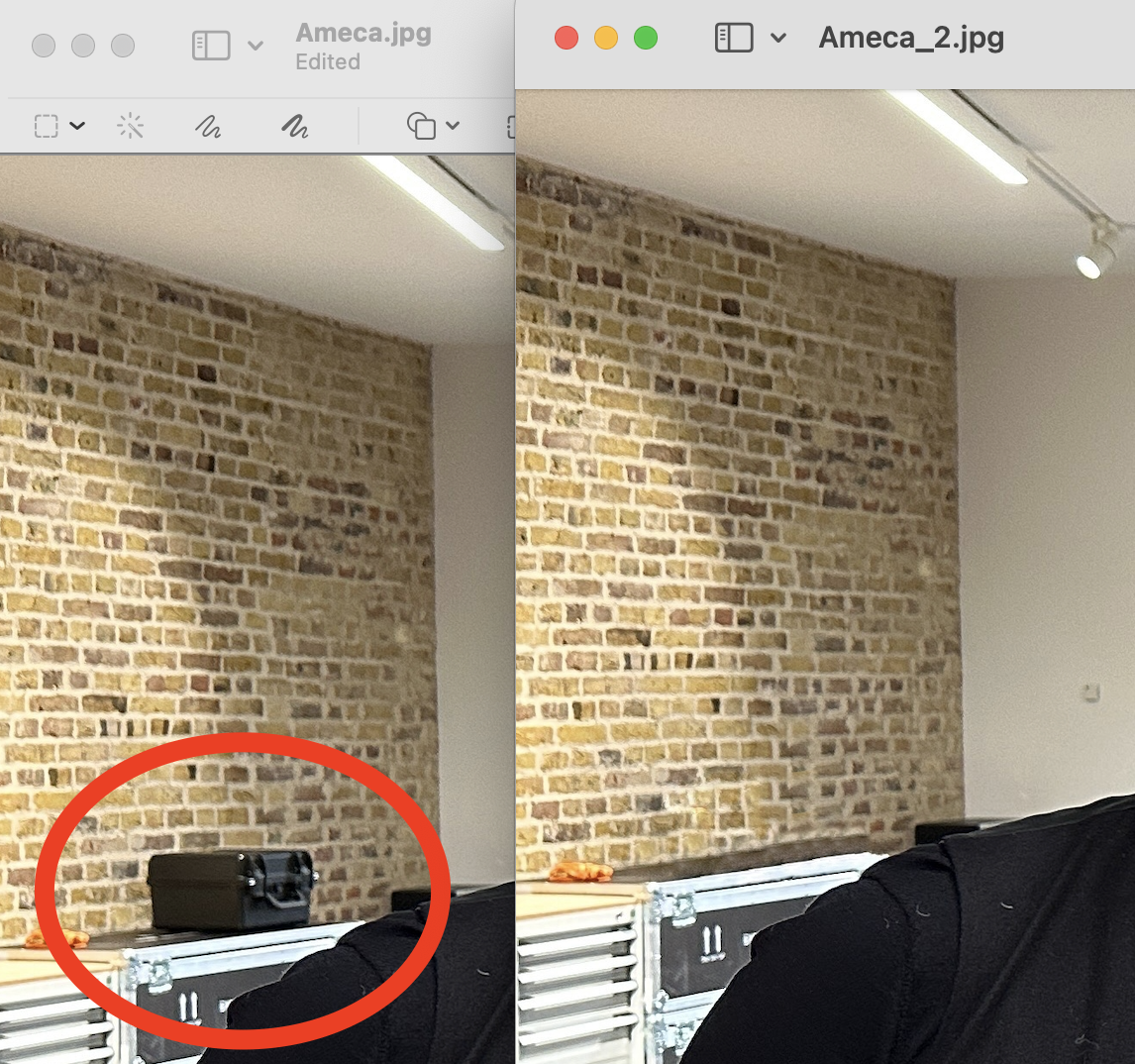
Differently from the hallucination, the two images were identical except that in the second image this element was not present:
Now, to close: imagine the AI we described so far, able to watch your screen and intervene when you are stuck, but accessible via voice, and able to answer you with its voice.
Here on Synthetic Work, we spend a lot of time talking about the emotional impact of voice interaction, and the potential of synthetic voices. And you know that OpenAI has now given ChatGPT five voices.
You should now see how these pieces are coming together, and why the company has received the astonishing valuation it has.
If you test all the prompting techniques we share in the Prompting section of the Splendid Edition, or if you try all the use cases we describe in the What Can AI Do for Me? section, or even if you simply use ChatGPT a lot, you’ll end up with a lot of chats.
Maybe you have spent hours crafting the ultimate prompt to turn GPT-4 into the perfect presentation builder or social media manager. You’d like to go back to that chat over and over, to get more advice on the same topic. Especially if you use the new Custom Instructions feature.
But no.
Your precious chat session is buried under hundreds of others, automatically titled in a way that didn’t seem that important to rectify at that time, but now makes it impossible to locate the conversation you need.
Because of this, the one feature that OpenAI should have introduced since day one is the capability to pin a chat session to the top of the list.
We are not asking for the moon. We are not asking for a fully-featured system of folder and tags.
Just a simple way to pin a few chats at the top. How hard can it be?
Harder than giving AI a synthetic voice, apparently.
But, as long as you use ChatGPT on the desktop, it’s just web technology. There must be a Chrome extension that can do this simple thing.
No. There’s not.
Or better, there is, as you’ll find out below, but it’s so buried below thousands of mediocre ChatGPT extensions, that finding it is a challenge in itself.
But this section of the Splendid Edition is here for this very reason: suggesting the best AI-focused/AI-related tools without you having to spend hours searching for them.
After dozens of disappointing experimentations, I can finally recommend a Chrome extension called Chat Organizer
It does a million things more than pinning chats, and you have to pay to access a large part of that million. But the pinning is reliable and free.
I tested it for a couple of weeks and I have no complaints other than the inevitable reload of the ChatGPT page to be sure that the pinned chats always remain where they should be.
It doesn’t even interfere with the introduction of new features: earlier this week, I finally got access to the GPT-4V model and Chat Manager didn’t skip a beat. But it might cause weird rendering if OpenAI modifies the layout of the page.
Before you rush to install it, remember that the extension can read everything in your browser window, so your interactions with ChatGPT are not private anymore.
I wouldn’t trust the developer to do the right thing with your data, so install it only if you have nothing to lose and you don’t discuss sensitive topics with ChatGPT.
Until OpenAI introduces a decent user interface, this is your best option. I’m sure it will happen after they invent an artificial general intelligence that invents reusable rockets able to fly to and from Mars on a daily basis fueled by a single cube of sugar.