
- A Chart to Look Smart
- More than 50% of surveyed UK undergraduates are using generative AI to help with their essays. They will be your future new hires.
- GitClear published a study on developers using CoPilot and found a decline in code quality.
- ARK Invest published its annual Big Ideas report, giving ample room to AI forecasts for this year and 2030.
- Prompting
- New research confirms that GPT-4 is capable of generative creative business ideas if prompted in the right way.
- The Tools of the Trade
- A little app to transcribe 45min YouTube video in 4 minutes.
You won’t believe that people would fall for it, but they do. Boy, they do.
So this is a section dedicated to making me popular.
More than 50% of surveyed UK undergraduates are using generative AI to help with their essays. They will be your future new hires.
From the official survey report of the Higher Education Policy Institute (HEPI), a UK think tank:
We polled 1,250 UK undergraduate students on their attitudes to generative artificial intelligence (AI) tools such as ChatGPT. Our key findings include:
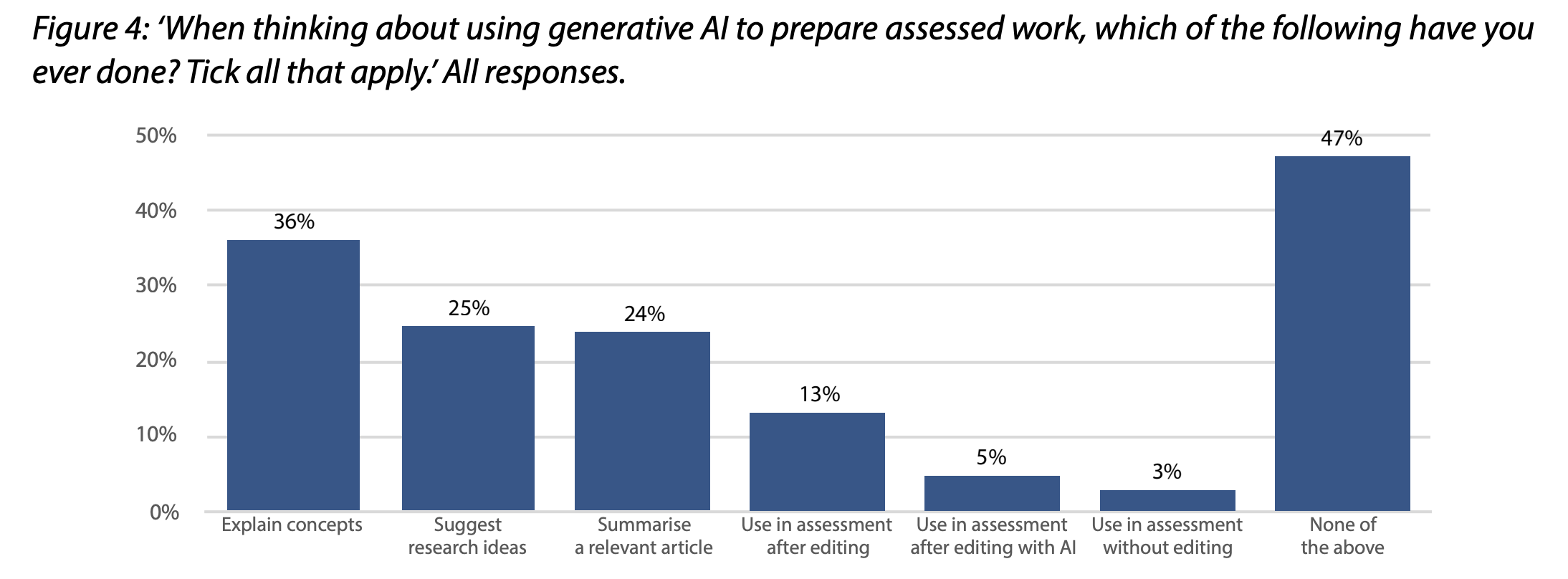
- More than half of students (53%) have used generative AI to help them with assessments. The most common use is as an AI private tutor (36%), helping to explain concepts.
- More than one-in-eight students (13%) use generative AI to generate text for assessments, but they typically edit the content before submitting it. Only 5% of students put AI-generated text into assessments without editing it personally.
- More than a third of students who have used generative AI (35%) do not know how often it produces made-up facts, statistics or citations (‘hallucinations’).
- A ‘digital divide’ in AI use may be emerging. Nearly three-fifths of students from the most privileged backgrounds (58%) use generative AI for assessments, compared with just half (51%) from the least privileged backgrounds. Those with Asian ethnic backgrounds are also much more likely to have used generative AI than White or Black students and male students use it more than female students.
- A majority of students consider it acceptable to use generative AI for explaining concepts (66%), suggesting research ideas (54%) and summarising articles (53%), but only 3% think it is acceptable to use AI text in assessments without editing.
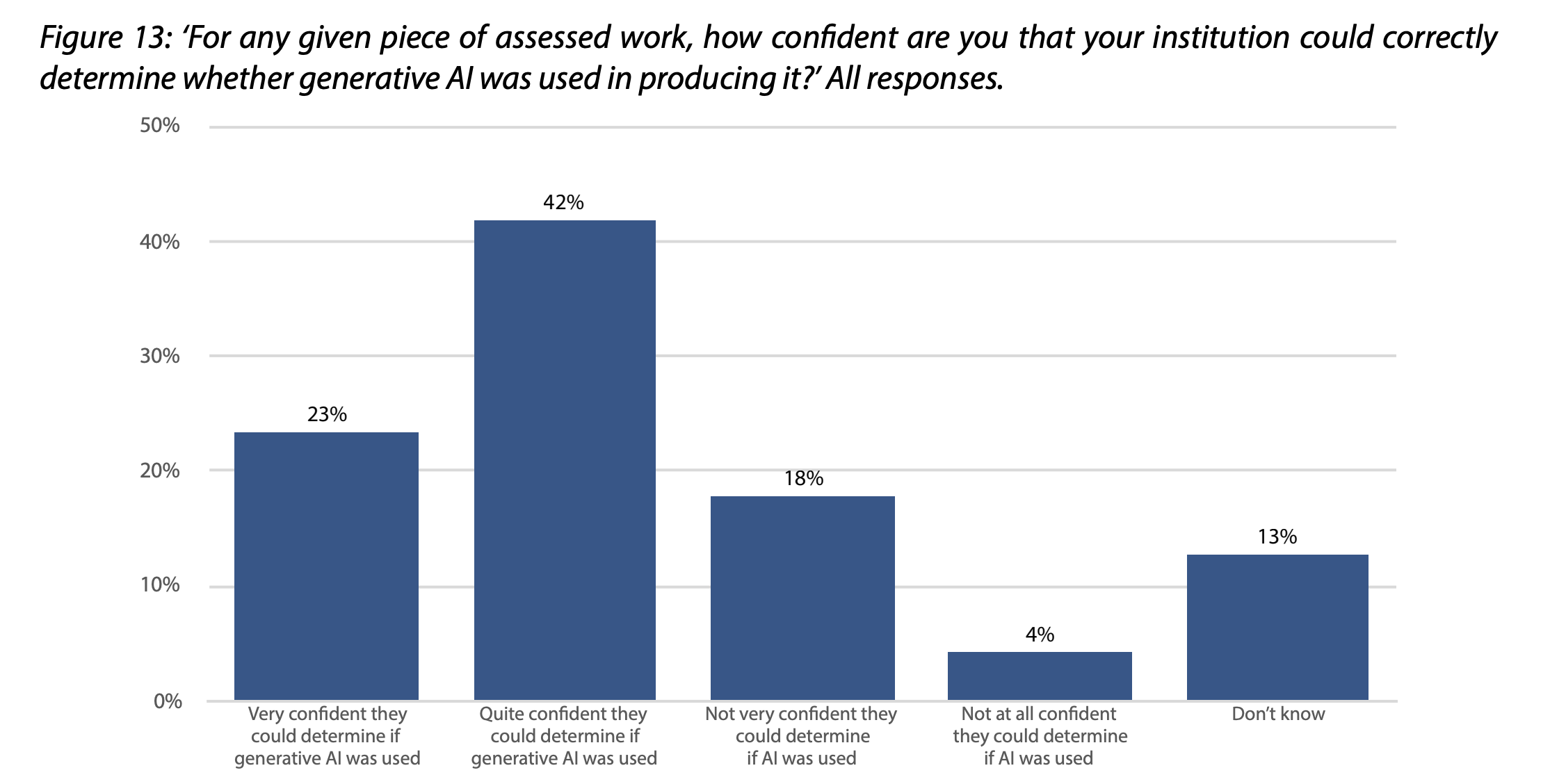
- A majority (63%) think their institution has a ‘clear’ policy on AI use, with only 12% thinking it is not clear. Most students (65%) also think their institution could spot work produced by AI.
- Institutions have not radically changed their approach to assessments, with only one-in-11 students (9%) saying the approach has changed ‘significantly’, compared with a quarter (24%) who say it has stayed the same.
- Students think institutions should provide more AI tools. While three-in-10 (30%) agree or strongly agree their institution should provide tools, only one-in-11 (9%) say they currently do so.
- Only a fifth of students (22%) are satisfied with the support they have received on AI. Most students (62%) are neutral or say they do not know.
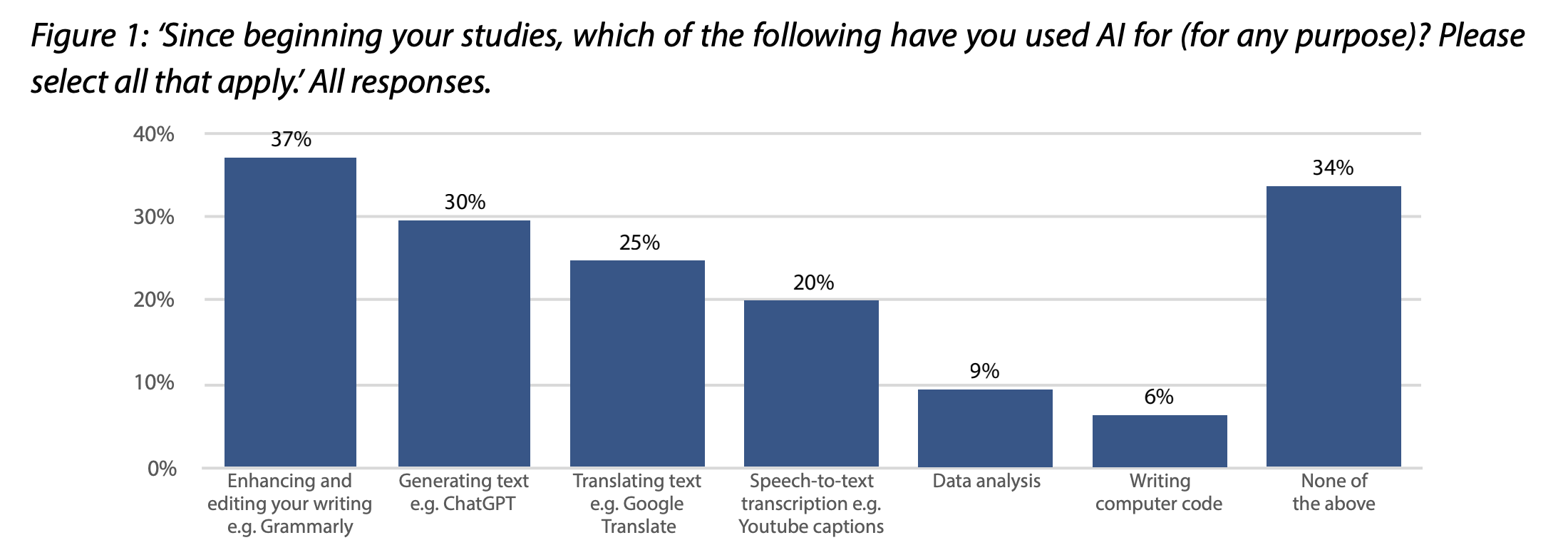
- Nearly three-quarters (73%) expect to use AI after they finish their studies. They most commonly expect to use it for translating text (38%), enhancing written content (37%) and summarising text (33%). Only a fifth of students (19%) expect to use it for generating text.
Being a student is a job. And what you learn while doing that job is what you carry with you in all your future jobs.
So, certainly, there is a business opportunity attached to this trend. But there’s also the urgency to rethink corporate policies that will apply to this new generation of workers.
People believe they can get away with it, and this sentiment will grow stronger as AI models become more capable:
GitClear published a study on developers using CoPilot and found a decline in code quality.
GitHub has published several pieces of research on the growth and impact of AI on software development. Among their findings is that developers write code “55% faster” when using Copilot. This profusion of LLM-generated code begs the question: how does the code quality and maintainability compare to what would have been written by a human? Is it more similar to the careful, refined contributions of a Senior Developer, or more akin to the disjointed work of a short-term contractor? To investigate, GitClear collected 153 million changed lines of code, authored between January 2020 and December 2023. This is the largest known database of highly structured code change data that has been used to evaluate code quality differences.
…
GitHub claims that code is written “55% faster” with Copilot. But what about code that shouldn’t be written in the first place?
…
Writing bad code faster implies considerable pains for the subsequent code readers. That is the first of many challenges facing developers who use an AI assistant. Others include:1. Being inundated with suggestions for added code, but never suggestions for updating, moving, or deleting code. This is a user interface limitation of the text-based environments where code authoring occurs.
2. Time required to evaluate code suggestions can become costly. Especially when the developer works in an environment with multiple, competing auto-suggest mechanisms
3. Code suggestion is not optimized by the same incentives as code maintainers. Code suggestion algorithms are incentivized to propose suggestions most likely to be accepted. Code maintainers are incentivized to minimize the amount of code that needs to be read (I.e., to understand how to adapt an existing system).
![]()
I would be amazed to discover that GitHub and Microsoft didn’t dedicate a significant amount of resources to solve #1. For no other reason than it’s a phenomenal business opportunity.
It makes no business sense to believe that GitHub wouldn’t do everything in its power to give developers a way to optimize and shrink their code base. First, there’s an incentive to increase application performance and, in turn, reduce cost. Second, a smaller code base is easier to secure.
But to achieve #1, I suspect GitHub (or any competitor) needs a larger and more reliable context window than the ones we can count on today. Accordingly, I would assume that this is an issue that will go with time.
#2 is a comment that I don’t fully understand, probably because I’m not a developer: if you insist on having multiple people whispering in your ear, of course you have an overhead in evaluating the suggestions you receive. If that’s your concern, then perhaps use only one AI model at a time to generate code suggestions.
#3 seems equally related to the size of the context window of available AI models. I would expect that, as technology evolves, tools like Copilot will go from suggesting new code solely based on the context of the open file, to the context provided by all the files in a certain directory, to all the files in a certain repository, to all project related to that repository.
And then, further down the line, I’d expect tools like Copilot to take into account the security best practices of that organization. Then, the security best practices of the entire industry. Then, the security vulnerability reports of the day, and so on.
So, perhaps, #1 and #3 are really issues, but I’d be optimistic that they will be mitigated with time.
Let’s continue:
A second, independent means to assess how code quality has changed in 2023 vs. before is to analyze the data from GitClear’s Code Provenance derivation. A “Code Provenance” assessment evaluates the length of time that passes between when code is authored, and when it is subsequently updated or deleted.
…
Code Provenance data corroborates the patterns observed in the Code Operation analysis. The age of the code when it is replaced has shifted much younger from 2022 to 2023. Specifically, code replaced in less than two weeks has jumped by 10%. Meanwhile, code older than one month was changed 24% less frequently in 2023 vs 2022 (19.4% of all changes vs. 25.5% previously). The trend implies that, prior to AI Assistants, developers may have been more likely to find recently authored code in their repo to target for refinement and reuse. Around 70% of products built in the early 2020s use the Agile Methodology, per a Techreport survey. In Agile, features are typically planned and executed per-Sprint. A typical Sprint lasts 2-3 weeks. It aligns with the data to surmise that teams circa 2020 were more likely to convene post-Sprint, to discuss what was recently implemented and how to reuse it in a proximal Sprint.
![]()
I can’t comment on this point as it’s far away from my area of expertise, but I don’t feel ashamed to ask a candid question: isn’t it possible that the exceptional speed and agility offered by Copilot is pushing developers to revise their code more frequently? An operation that, before the advent of code assistants, people would have avoided as much as possible?
ARK Invest published its annual Big Ideas report, giving ample room to AI forecasts for this year and 2030.
Some of you know that I am a former Gartner analyst and for my entire career, before and after being an analyst, I always said that one thing analysts should never do is to make predictions.
Humans are terrible at predicting the future and every industry firm on the market, including Gartner, has been proven wrong time and time again.
Of all the technologies and markets I looked into in my career, artificial intelligence is the hardest to predict because the technology evolves faster than any other I’ve ever seen, and the discoveries made by the AI community on a weekly basis are so radical that they can change the market outlook in a matter of months.
So, read the ARK Invest 163-slide report with much skepticism.
Synthetic Work already published many of the charts that are in the report, as they have been released throughout the year, but there are a few new forecasts that are worth mentioning.
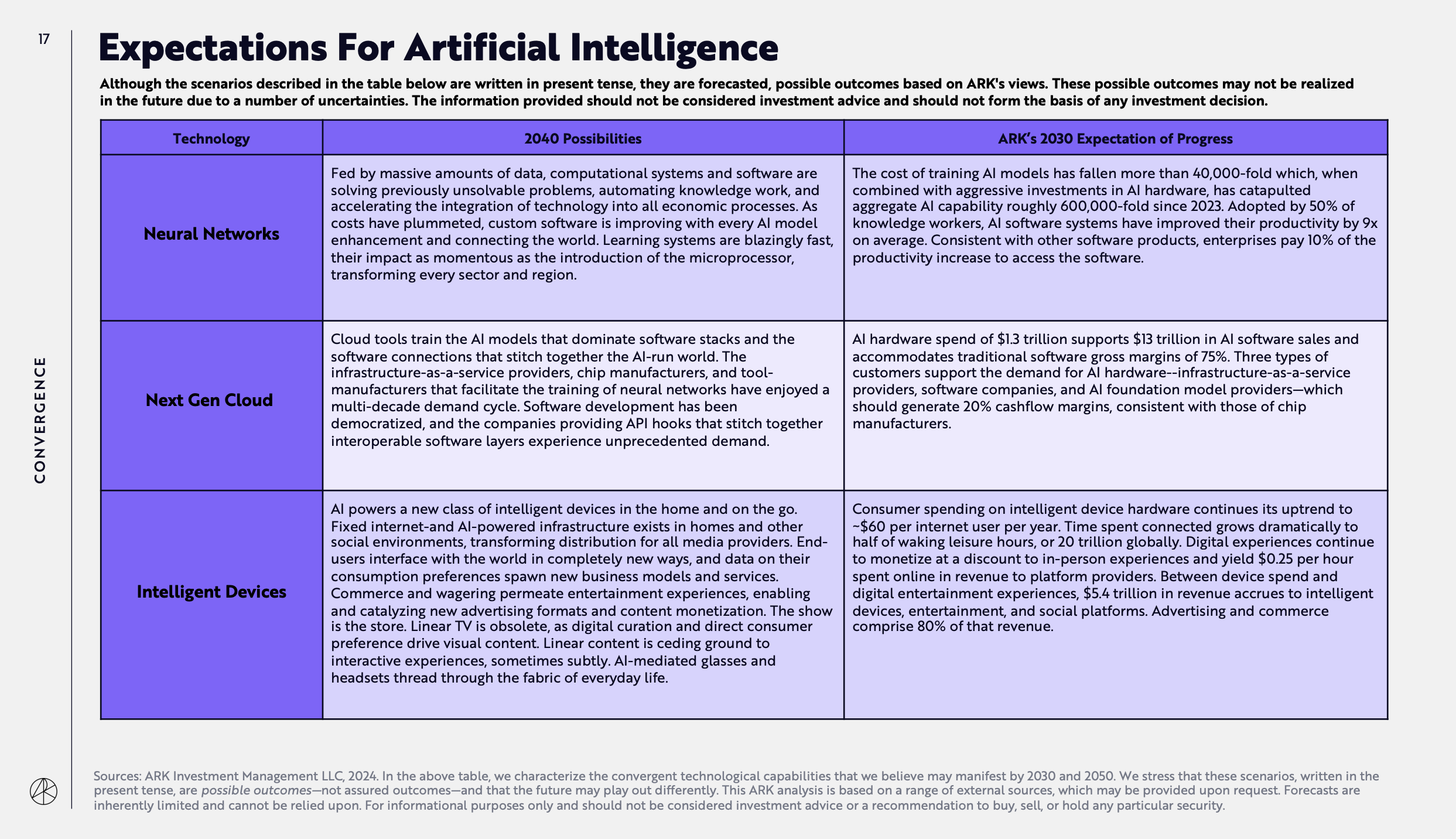
The first is the most important, squarely within the scope of this newsletter. It’s about the adoption rate by knowledge workers by 2030 and its subsequent impact on business productivity:
The second is about the expected increase in the inference performance of AI models for this year:
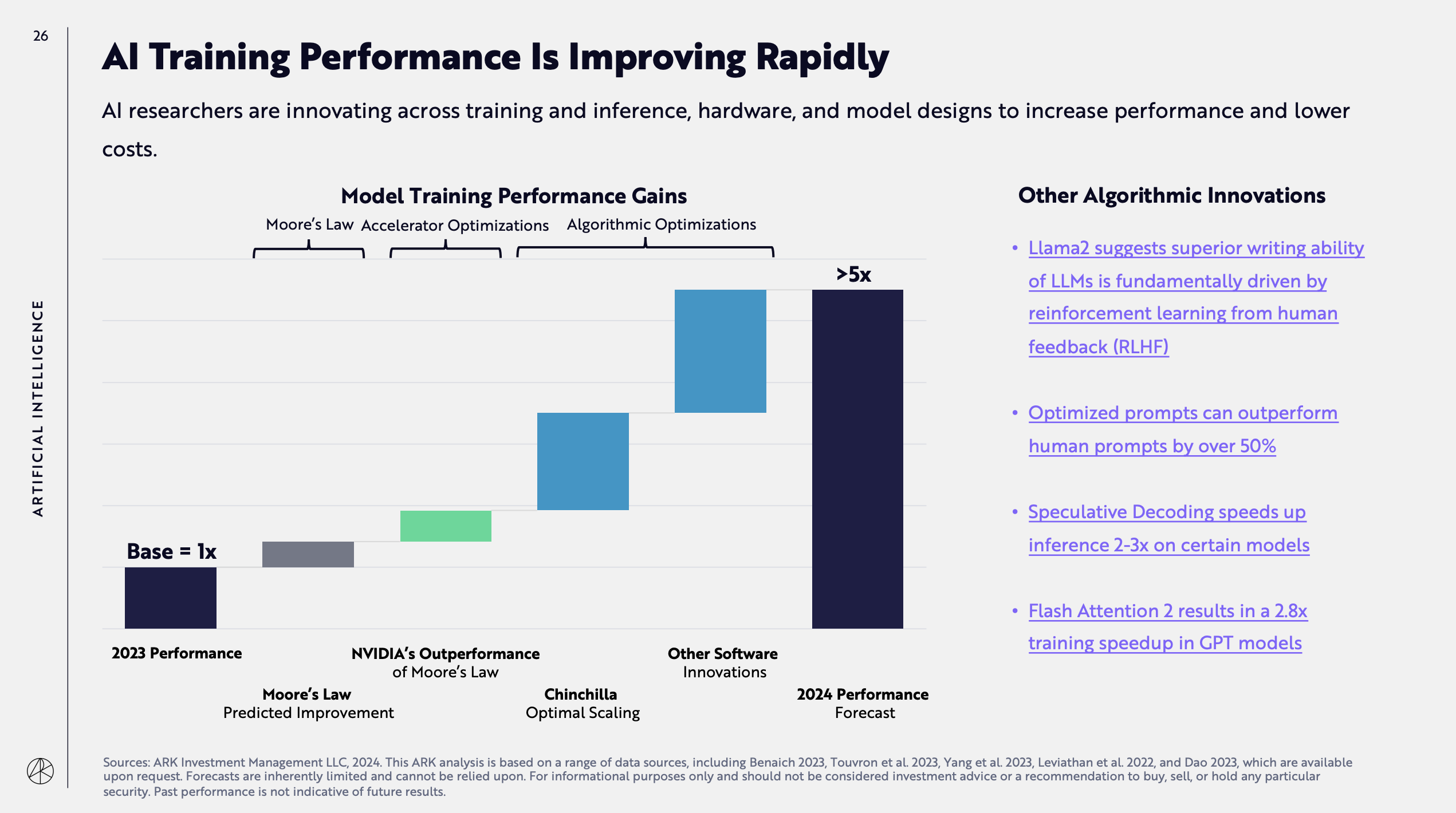
The third is about the projected year-over-year cost decrease trend for AI model training:
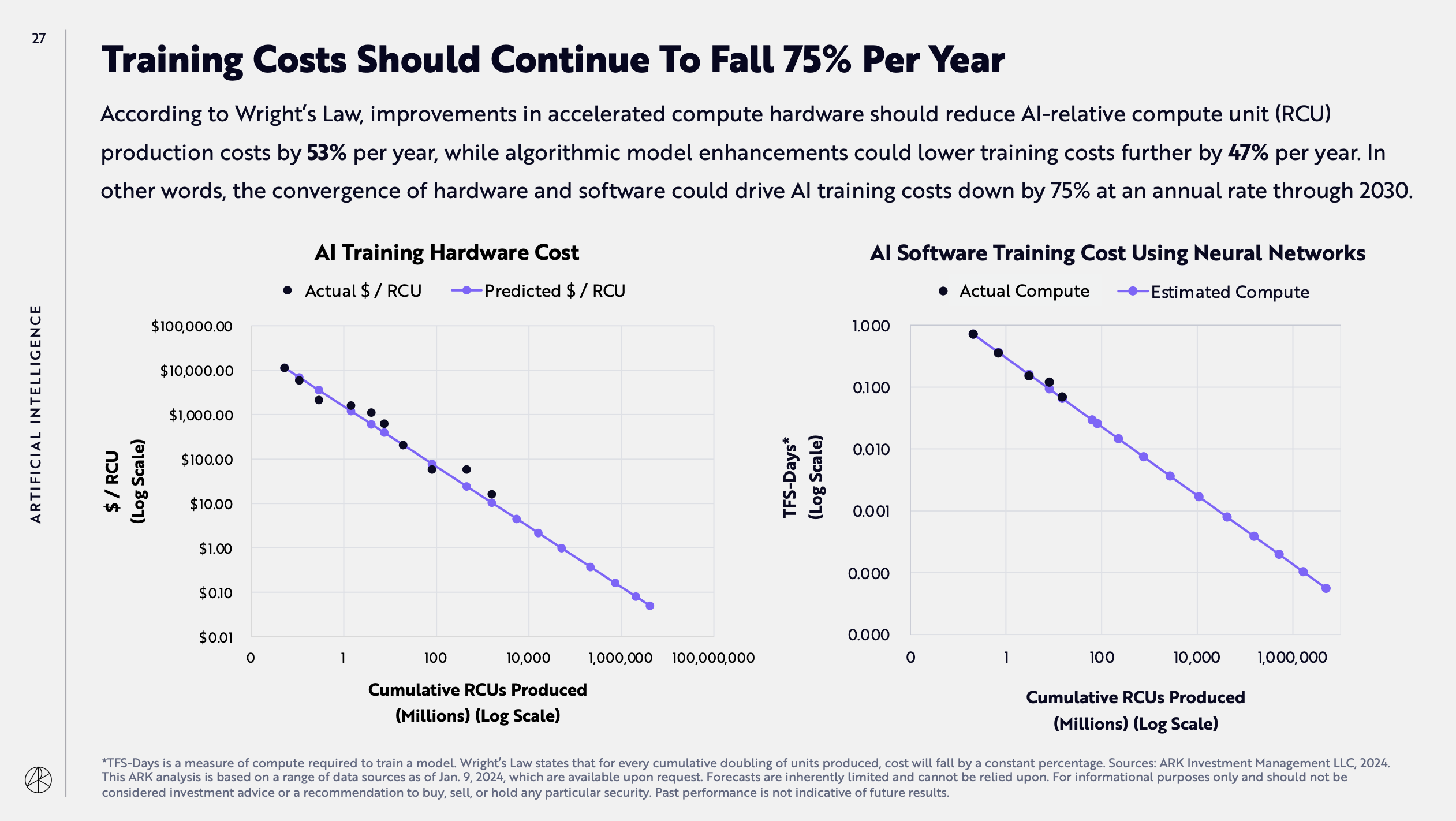
The fourth is about when we’ll run out of tokens to train AI models. The answer is: this year.
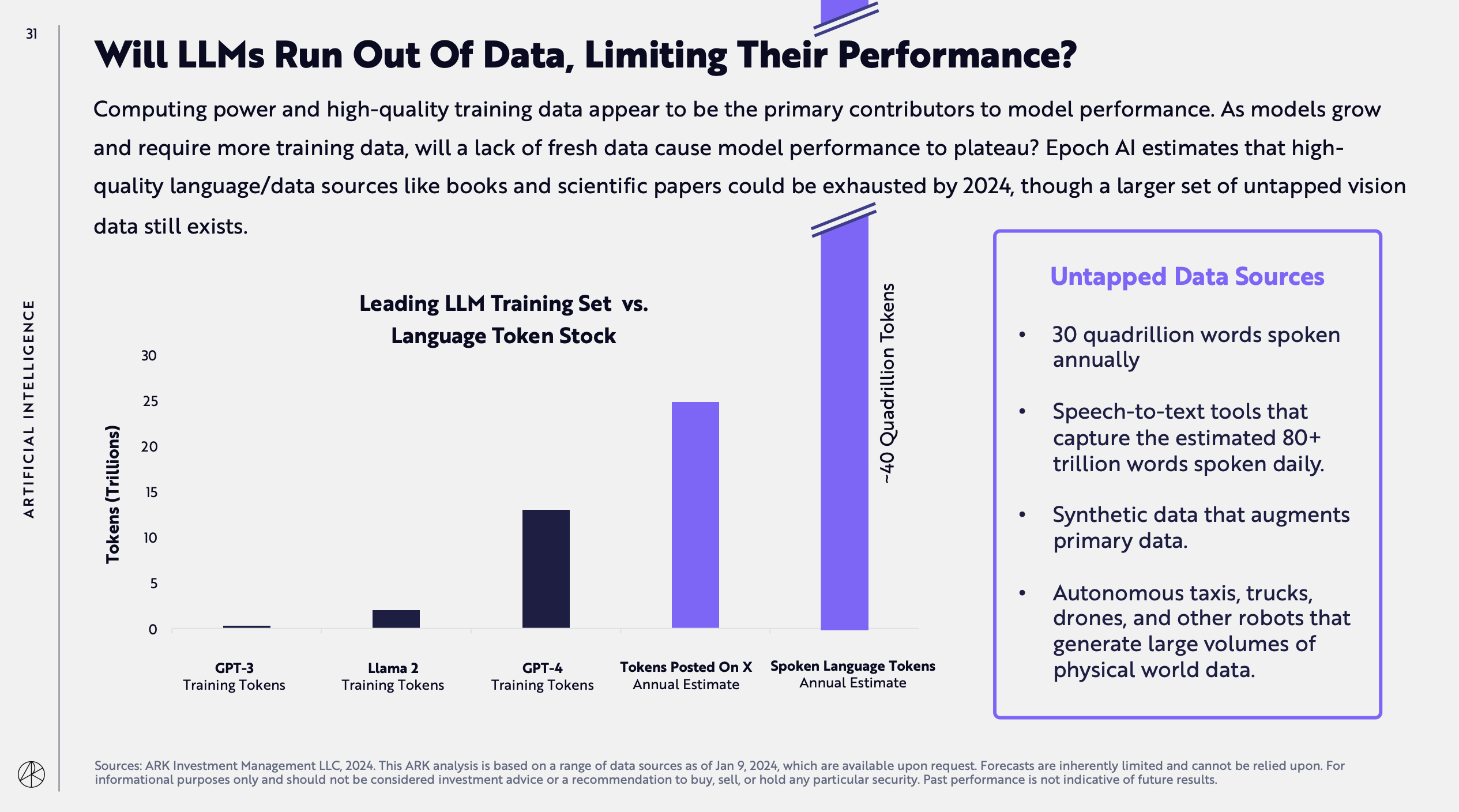
This is very relevant to what you have read / will read in this week’s Free Edition of Synthetic Work. It also highlights a growing pressure to explore training from videos, something I’ve been talking about for years.
The last forecast to pay attention to is about the expected total addressable market (a term I have no sympathy for) and the CAGR for software:
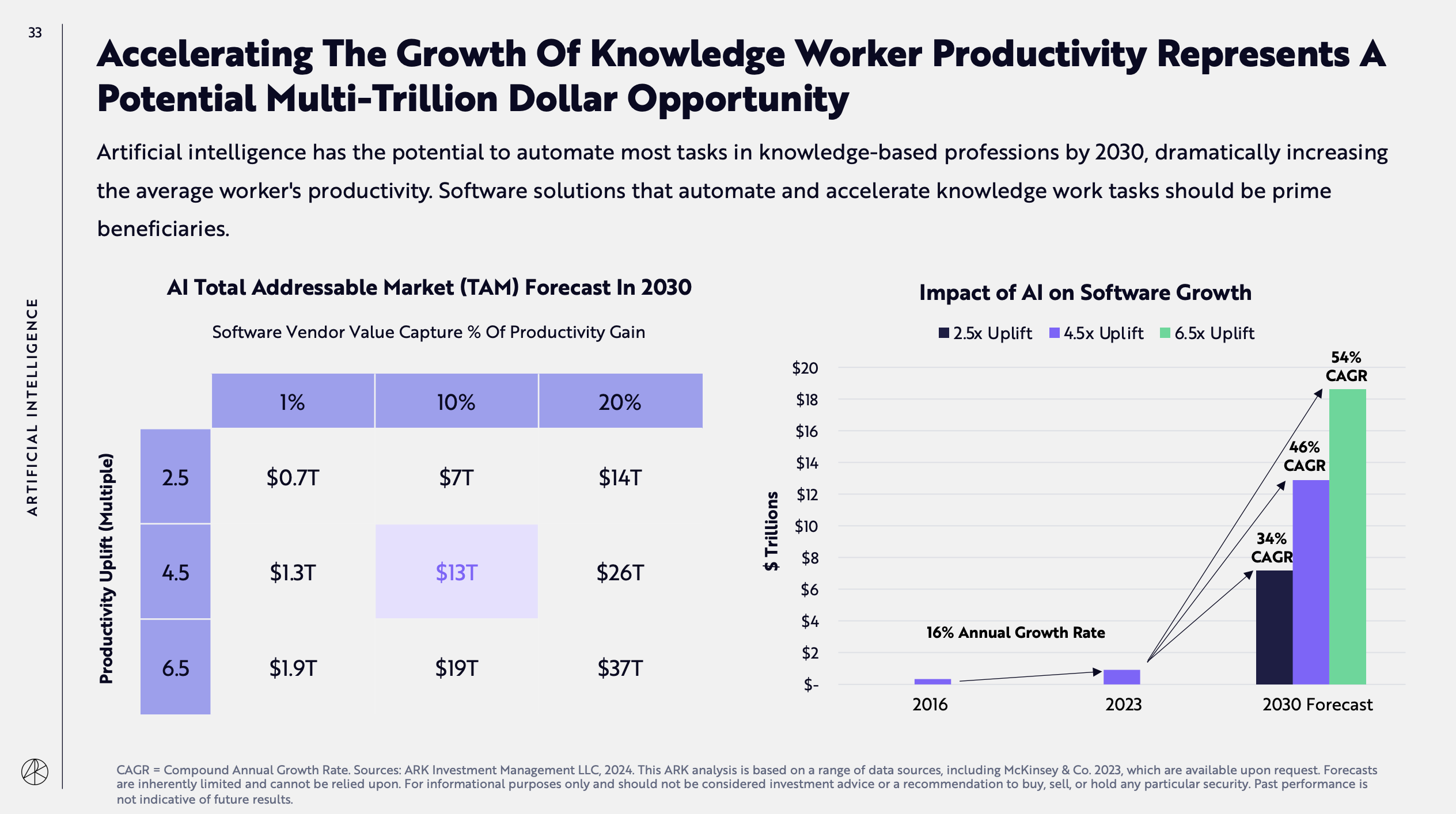
The interpretation of these charts and many others in the report is not straightforward and requires a deep understanding of the AI technologies that are being developed and underpin many of the assumptions made in the report.
Be careful if you plan to build your business strategy on these forecasts.
Before you start reading this section, it's mandatory that you roll your eyes at the word "engineering" in "prompt engineering".
New research confirms that GPT-4 is capable of generative creative business ideas if prompted in the right way.
Long-time readers of Synthetic Work might remember Issue #24 – The Ideas Vending Machine, where I showed you how to use GPT-4 to generate valid and original business ideas.
You might also remember that, on that occasion, I was quite skeptical about the quality and variety of the ideas a generative AI model could generate, but I had to change my mind as GPT-4 suggested ideas that I had considered myself long before the experiment.
New research from The Wharton School, University of Pennsylvania, confirms that GPT-4 can indeed generate original and diverse business ideas, almost as good as the ones generated by humans using top brainstorming and design thinking techniques, but it needs to be prompted in the right way.
From the paper, titled Prompting Diverse Ideas: Increasing AI Idea Variance:
Across the fields of computer science, entrepreneurship, and psychology, there exists an exploding interest in using AI to generate ideas and to alter and augment the practice of brainstorming. However, despite the ability of AI systems to dramatically increase the productivity and quality of the idea generation process, they appear to grapple with creating a wide dispersion of ideas (i.e., ideas are too similar to each other, see Dell’Acqua et al 2023), which inherently limits the novelty (Girotra et al 2023) of the ideas, the variance of the idea quality, and ultimately, and most importantly, the quality of the best ideas.
The apparent lack of dispersion in a set of AI generated ideas motivates our main research question we aim to address in this paper. How might one increase the diversity of an AI generated pool of ideas? Since our primary focus is on AI in the form of large language models (LLMs), increasing the diversity of a pool of ideas boils down to a matter of prompt engineering. We thus refine our research question to: How might one choose prompts in LLMs to increase the diversity of an AI generated pool of ideas?
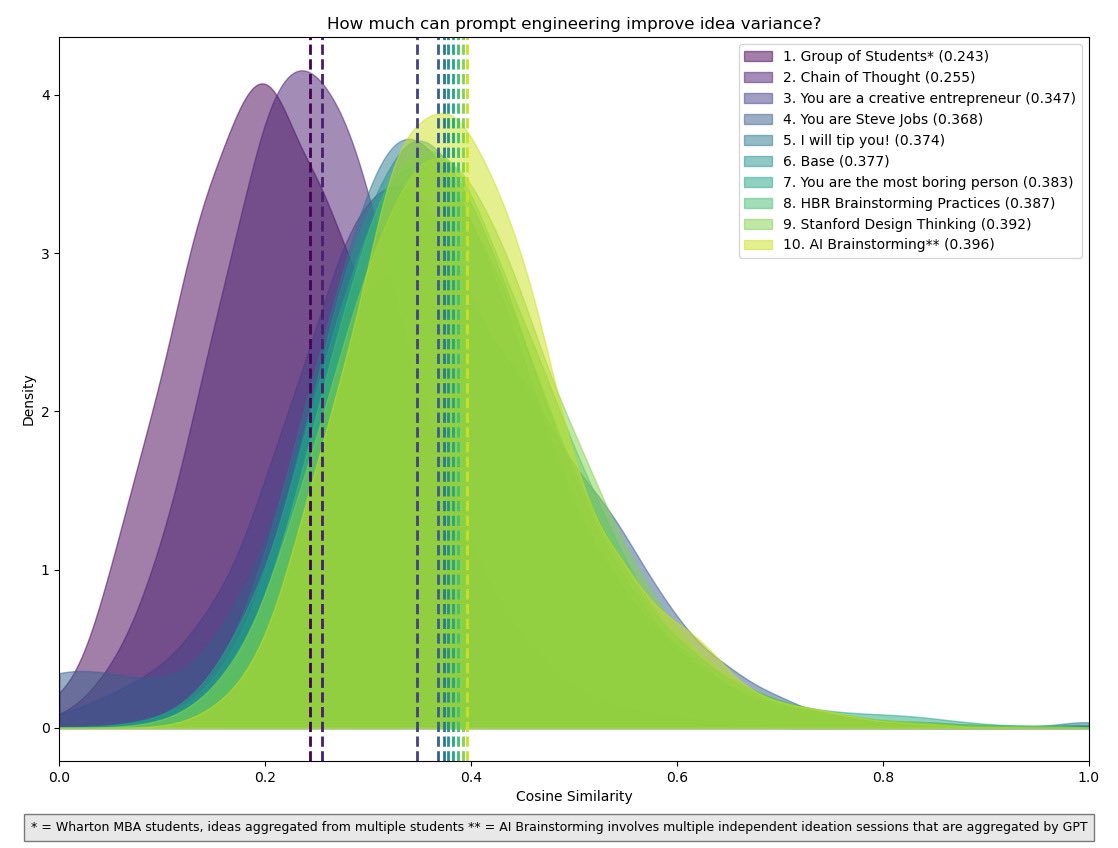
To find out what prompts lead to the most diverse idea pools, we compare multiple prompting strategies. This includes (1) minimal prompting, (2) instructing the LLM to take on different personas, (3) sharing creativity techniques from the existing literature with the LLM, and (4) Chain of Thought (CoT) prompting which asks the LLM to work in multiple, distinct steps. As outcome metrics we use the Cosine Similarity (Manning 2008) of the idea pool, the total number of unique ideas that can be identified by a prompt, and the speed at which the idea generation process gets exhausted and ideas start repeating themselves (see Kornish and Ulrich 2011).
…
Our main findings are as follows:
- We confirm the diversity achilles of AI generated brainstorming by showing that pools of ideas generated by GPT-4 with no special prompting are less diverse than ideas generated by groups of human subjects. Specifically, we find that (a) Cosine similarity for ideas generated by groups of humans is around 0.243 compared to 0.255 – 0.432 for GPT-4 generated ideas.
- Comparing an array of prompts that vary in wording and in problem solving strategy, we show that the diversity of AI generated ideas can be substantially improved using prompt engineering. For example, we show that instructing GPT-4 to think like Steve Jobs is effective in increasing the diversity of the resulting ideas (0.368 cosine similarity versus the baseline of 0.377) while prompting GPT-4 with recommended creativity tools published by the Harvard Business Review (cosine similarity of 0.387) less so. Overall, we compare 35 prompts in their ability to reduce cosine similarity, increase the number of unique ideas, and keep the ideation process from fatiguing.
- In the comparison of prompting strategies, we show that Chain-of-Thought (CoT) prompting leads to one of the highest diversity of the idea pools of all prompts we evaluated and was able to obtain a diversity nearly as high as groups of humans. CoT prompting breaks up the overall brainstorming task into a series of micro tasks and has been found to be highly effective in other LLM applications such as solving mathematical problems (see Wei et al 2022). We further show that CoT increases the number of unique ideas that can be generated in our domain from around 3700 for the base prompt to 4700.
To craft the various prompts used in the study, the authors used a variety of prompting techniques and traditional brainstorming best practices. Roughly, the prompts they came up with can be divided into eight groups:
- Idea Prompted GPT: Prompted with seven successful ideas from prior research (same pool as in Girotra et al 2023)
- HBR trained GPT: Prompt includes a paper on best practices in brainstorming published in the Harvard Business Review
- Design Thinking GPT: Prompt includes an article on design thinking by Stanford
- Special Techniques: Involves prompts that offer tipping, plead with the model emotionally, and threaten to shut it off amongst others.
- Persona Modifiers: Starting with a base prompt, these pools tell the model they are widely known personas, such as Steve Jobs or Sam Altman. It further includes less concrete personas, such as “extremely creative entrepreneurs” adding modifiers such as asking for ideas to be “good”, then “bold”, then “diverse and bold.
- Hybrid brainstorming: Pool consists of ideas combined from 40 different GPT-4 sessions, picking and refining the best ideas from 4 of them at a time as explained above
- Similarity information: Informed GPT-4 about the cosine similarity of existing ideas.
- Chain-of-Thought: Asking GPT-4 to first generate a short list of 100 ideas, then making them bold and different, then generating descriptions for them
The one prompt that most closely matched the diversity of ideas generated by groups of human subjects was in the last group:
Generate new product ideas with the following requirements: The product will target college students in the United States. It should be a physical good, not a service or software. I’d like a product that could be sold at a retail price of less than about USD 50. The ideas are just ideas. The product need not yet exist, nor may it necessarily be clearly feasible. Follow these steps. Do each step, even if you think you do not need to. First generate a list of 100 ideas (short title only) Second, go through the list and determine whether the ideas are different and bold, modify the ideas as needed to make them bolder and more different. No two ideas should be the same. This is important! Next, give the ideas a name and combine it with a product description. The name and idea are separated by a colon and followed by a description. The idea should be expressed as a paragraph of 40-80 words. Do this step by step!
If you are curious, the paper contains all the other prompts evaluated in this study. They are good examples of what you shouldn’t do when you prompt your AI model.
The irony of all of this is that one of the three authors of the paper spends a huge amount on social media networks promoting the idea that prompt engineering is not necessary and people should not bother learning how to improve their communication with their AI models.
Yet, week after week, he publishes research (now including his own) and empirical evidence that prompt engineering makes a material difference in the quality of the answers you get from large language models.
The readers of the Splendid Edition of Synthetic Work had almost one entire year of weekly proofs prompt engineering can impact your AI productivity.
At the beginning of last year, Synthetic Work covered a wonderful little application for macOS called MacGPT, built by the independent developer Jordi Bruin.
It’s really just a wrapper for the OpenAI APIs, and there’s no difference in terms of results between using MacGPT and using the official ChatGPT website or mobile app.
The difference, worth the money Bruin charges, is in how well the wrapper allows OpenAI model to integrate with the macOS environment. I won’t repeat myself. If you missed it, go read Issue #12 – And You Thought That Horoscopes Couldn’t Be Any Worse.
The same developer created other wrapper apps for other OpenAI models, including Whisper.
Whisper is the state of the art in transcribing audio and video content, far surpassing any technology we ever had. And OpenAI releases it for free to the public. In fact, it even regularly updates the model to increase its accuracy.
We occasionally mentioned Whisper in past issues of Synthetic Work, and we mentioned that, on certain industrial GPUs, this AI model is capable of transcribing 150 minutes of audio in less than 2 minutes.
But I am afraid I failed at clarifying the tremendous progress made by the AI community in optimizing Whisper to run at astonishing speeds on consumer-grade hardware. Like your laptop and mine.
So today I bought the Pro edition of the Whisper wrapper developed by Jordi Bruin, called MacWhisper, to show you what we are talking about.
First: why buy the $29 Pro edition? If you don’t, the Free edition will be limited to the small version of the Whisper model, which is not as accurate as the Large model that comes with the Pro edition.
But it’s not just that: the Pro edition also includes a host of features that greatly improve your quality of life, like the capability to transcribe a YouTube video without downloading it first on your computer, the capability to record the audio of any app running on your computer and transcribe whatever is said in real-time, the capability to correctly identify multiple podcast speakers and transcribe their speech in isolation, or the capability to translate the transcription thanks to the integration with the popular AI-powered translator DeepL.
Even without all these extra features, the capability to use the Large model is a must-have if you need transcriptions for professional reasons.
So, how fast has Whisper become on consumer-grade hardware thanks to two years of optimizations developed by the AI community?
So fast that, on my machine (which does NOT have a GPU), the 45 minutes and 35 seconds YouTube video of the OpenAI Dev Day keynote, has been transcribed in 4 minutes and 08 seconds.

A similar app for Windows, run on a laptop with a GPU, would transcribe even faster.
This is an enormous productivity boost for all those professional categories that must analyze recorded audio: journalists, lawyers, doctors, analysts, researchers, assistants, emergency services, PR/AR, and so on.
So much knowledge is trapped in YouTube videos and podcasts that are hard or impossible to transcribe.
And where you need to capture the content of a meeting or a lecture, where there’s not even the technical option to generate a transcription, a tool like MacWhisper is a game-changer.
As you would expect from a tool like this, once the transcription has been generated, you can export it in a variety of formats, including the subtitle format, in case you need to further manipulate the content in a video editing software. And, you can group the exported transcription by speaker or sentence, which greatly increases the readability of the transcription.
And when you are done exporting, you discover a last gem, another feature of the Pro version: the seamless integration with OpenAI models to do things like summarizing the transcription or creating a mindmap out of it.
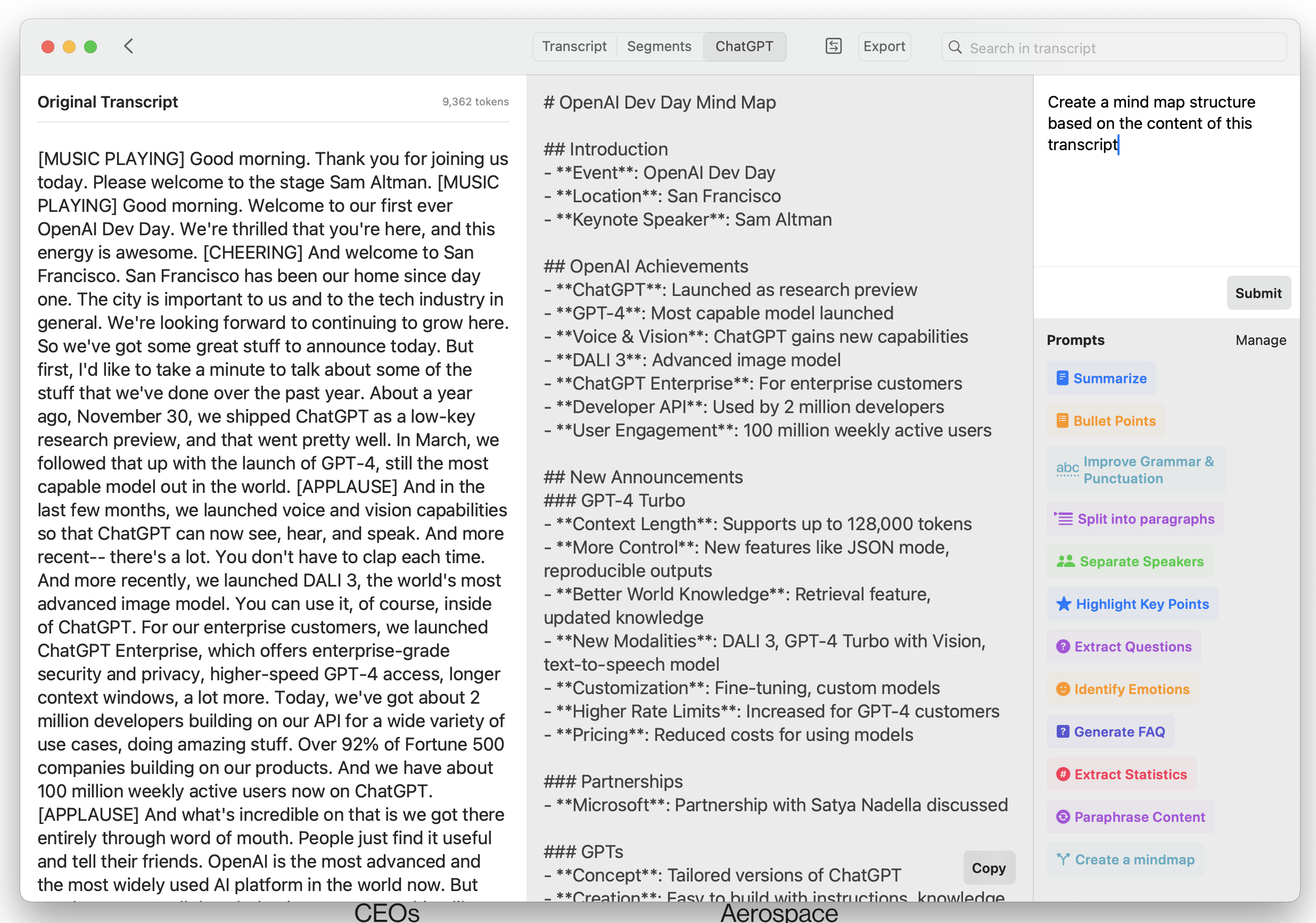
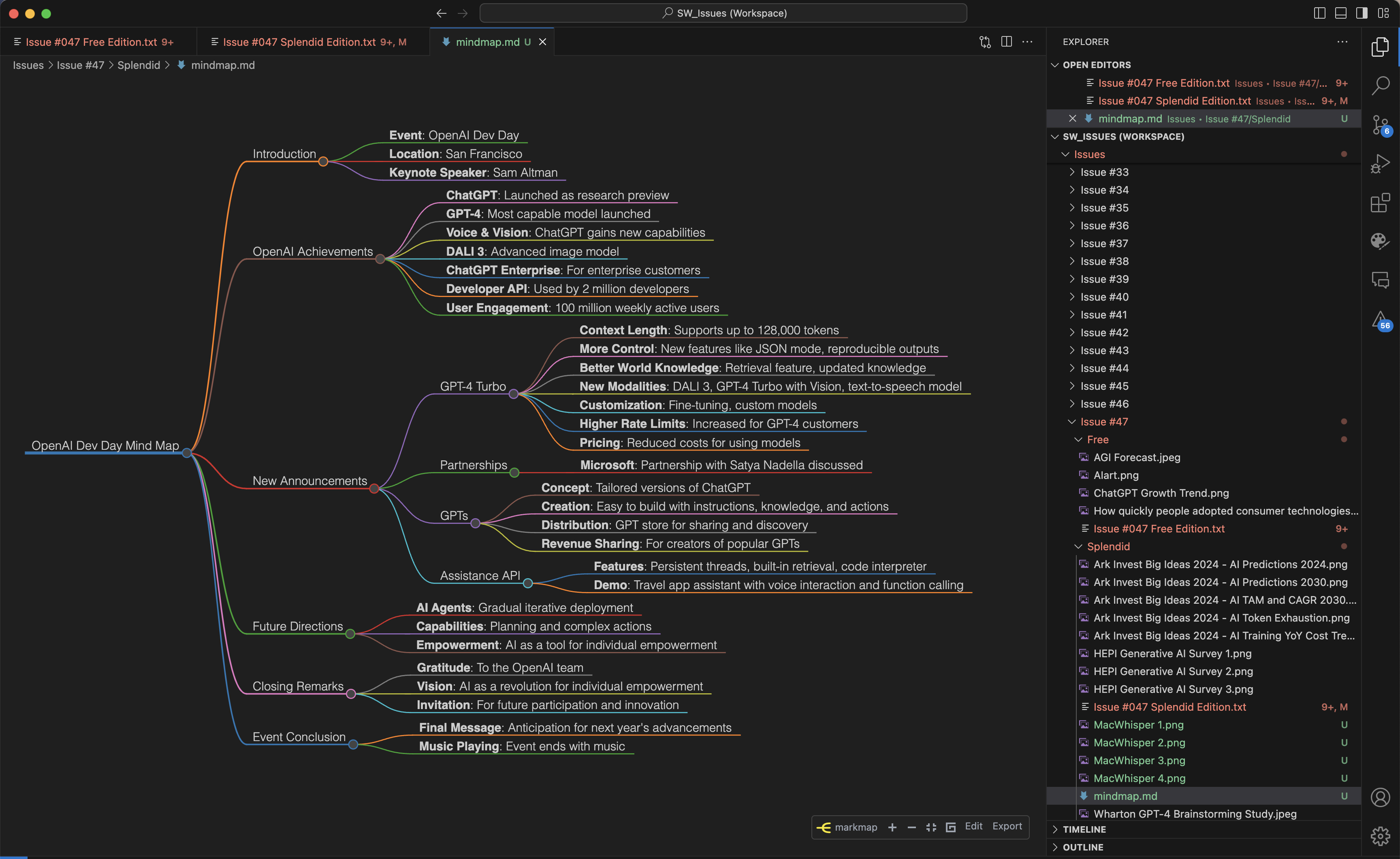
Request a mindmap, which OpenAI models will happily generate for you with Markdown syntax, save it in a .md file, and then open it inside your favorite mindmap software.
Here’s the very mindmap of the OpenAI Dev Day keynote displayed inside VS Code with the Markmap extension:
You don’t have to use the predefined prompts that come with MacWhisper. You can either write the prompt you want every time, or you can customize the predefined prompts according to your specific needs:
I don’t know if there’s an app like MacWhisper for Windows and Linux, but if you have a Mac, this is a must-have.