
- Generative AI is turning people that don’t know how to code into coders, and software engineers into software engineers with 1000x the attitude
- GPT-4 is no longer your copilot, it is now your captain as it builds the app your worked 3 weeks on in just 30 minutes
- Developers are already thinking about new programming languages designed to work with large language models
- It turns out that the AI can be pushed to role-play as an expert, explain its reasoning, and/or self-plan to massively improve the generated output
- It also turns out that the AI can create imaginary worlds that follow rigid rules: like when it pretends to be a Linux terminal
- It also turns out that you can use AI to automatically correct bugs in your mediocre code, creating a “self-healing” program
- Meanwhile, somebody managed to replace the brain of Siri with GPT-3 and the answers you get, finally, don’t cause you fits of anger
- The next step, as shown by Meta AI, is an AI that can learn what’s the best API to call to achieve the goal indicated in your prompt
- The next-next step is replacing all legacy backends like databases with a large language model.
Alright. Time to talk about the impact of AI on software development.
This is a theme I’m especially close to because I’ve spent the last 13 months of my past life (when I was responsible for the business and product strategy of the automation business in Red Hat) on it.
During that experience, I worked side by side with an IBM Fellow (a rare privilege), VP, and Chief of Research at IBM Research. This person is also the former CTO of IBM Watson, the AI that beat humans in the TV show Jeopardy in 2011. An even rarer privilege.
Five years ago, way before GitHub Copilot was a thing and the entire world would go crazy for ChatGPT, I started thinking about using machine learning to generate automation workflows for Ansible, the open source automation software that Red Hat acquired in 2015 (I was part of the acquisition team, too).
Struggling to find the expertise and support within Red Hat at that time, I shelved the idea for 3 years. However, thanks to IBM’s acquisition of Red Hat in 2019, I had a chance to convince this Chief of Research in IBM Research to pursue the opportunity.
The idea was received with enthusiasm and, as result, I had the privilege to lead a team of brilliant machine learning engineers that helped me bring to life a 5 years old idea as what the world has known as Project Wisdom.
1/ Finally, I can unveil *a glimpse* of the project I've been working on for over 1 year with @IBMResearch: Wisdom.
We will superpower #automation with the incredible capabilities of #AI: https://t.co/zB7HKiFTNC
— Alessandro Perilli ✍️ Synthetic Work 🇺🇦 (@giano) October 18, 2022
Then, I left Red Hat and now, I’m here telling you all about how AI is changing the world of software development.
Alessandro
What we talk about here is not about what it could be, but about what is happening today.
Every organization adopting AI that is mentioned in this section is recorded in the AI Adoption Tracker.
I’ll spare you the part where I say that generative AI is changing how quickly software developers write code (up to 55% faster), how much AI-assisted code they write (46%), and how happy they are about it (75% happier). To the point that people are now talking about software engineers + large language models as “10x/100x/1000x engineers”.
As a side note, let’s hope these multipliers are just about productivity. I can’t imagine dealing with engineers that are 1000x more convinced to be right than they already are today.
And I’ll spare you the part where I say that developers have just started learning to co-write code with AI that we are already seeing the next level of this interaction.
For example, I will not mention that GitHub has announced Copilot X, based on GPT-4, which generates a software patch for their questionable code when they run it and a bug crashes it. Or that Copilot X can submit pull requests on their behalf.
I will not say that somebody has already joked that “He is no longer your copilot, he is now your captain.”
Equally, I will not mention that somebody is building a way for a large language model to modify ALL files in a code repository to comply with whatever request the user submits:
🤔 What comes after Copilot?
My take: a conversation with your codebase!
Introducing Tensai, your repo-level code assistant
❔ Ask complex questions
✅ Automatically generate PRs for complex taskshttps://t.co/HEZJRpOaf5More👇 pic.twitter.com/tL8CF7cnbK
— Jay Hack (@mathemagic1an) January 2, 2023
I will not say that some of the things I did not mention are, to developers, equal to witnessing a repeat of the Miracle of Fátima for a Christian peregrine.

Don’t believe me?
Lmao! No way GPT-4 just built an application (that took me 3 weeks) in under 30 minutes 😭💀
— kode maazi (@coderboy_exe) March 18, 2023
Not convincing enough? What about this:
Can confirm. Just yesterday, my teammate wrote a custom JSON parser that would have been a slog for 1-2 days within hours using GPT4. GPT4 is like giving each engineer their own intern who does 70-80% of the job. The remaining 30% is constraints & biz logic. Startups are going… https://t.co/EfR22oU2vI
— Apoorva Govind (@Appyg99) March 17, 2023
Now. The reason why I will not mention any of these things is that they are not the interesting things in this issue of Synthetic Work.
What’s interesting is that generative AI is not just changing the way people write code. It’s changing the way people think about programming languages.
To illustrate this point, let me start with Amjad Masad, the CEO of Replit, one of my startups worth watching. Replit is an online IDE (the type of software developers use to write code) used all around the world by students and professionals alike.
Replit is also the only IDE that offers an alternative to GitHub Copilot. While Copilot uses a fine-tuned version of OpenAI Codex, a large language model that came before ChatGPT, Replit uses its own AI model to power a service called Ghostwriter.
Differently from Copilot (but similarly to Copilot X – Github might have been quite a bit inspired by Replit here…), Ghostwriter allows the user to chat with the AI to explain what’s wrong about a portion of the code, or to generate a diff to correct it:
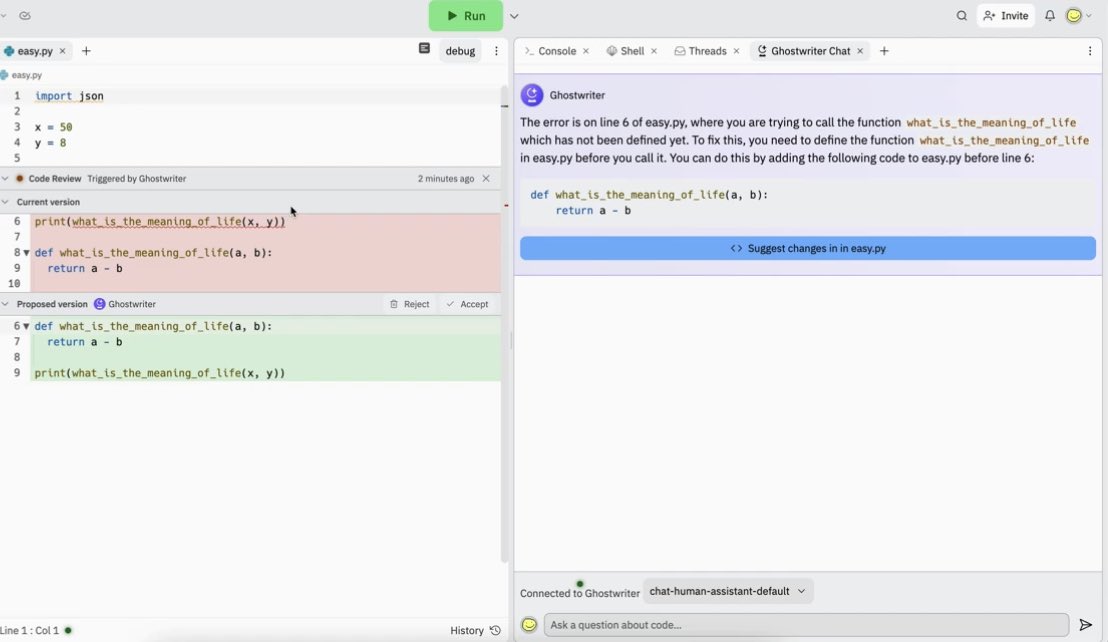
Replit AI could do better. And probably it will: just this week, Replit announced a partnership with Google and a switch to their AI models for Ghostwriter.
As often here on Synthetic Work, we care absolutely nothing about all of this. It’s just for context. What we care about is this:
There is a huge opportunity to make a programming language that is optimized for LLMs to write so they produce more straightforwardly correct and optimizable code.
— Amjad Masad ⠕ (@amasad) January 20, 2023
In other words, rather than waiting for AI to become better at understanding developers requests in natural language and generate fewer hallucinations, maybe it’s possible to rethink how a programming language looks like, to facilitate the AI job.
Not in response to Amjad, but coincidentally relevant for this conversation, we have a comment made by Andrej Karpathy. Andrej is a founding member of OpenAI, which he left in 2017 to work as Director of AI and the Autopilot Vision program in Tesla.
He just rejoined OpenAI and his Twitter bio says that he’s working on the OpenAI version of Iron Man’s JARVIS.
What matters more for our conversation today is that he said:
The hottest new programming language is English
— Andrej Karpathy (@karpathy) January 24, 2023
Andrej is clearly working on something because just 2 months later he writes:
A file I wrote today is 80% Python and 20% English.
I don't mean comments – the script intersperses python code with "prompt code" calls to GPT API. Still haven't quite gotten over how funny that looks.— Andrej Karpathy (@karpathy) March 4, 2023
So what’s happening here?
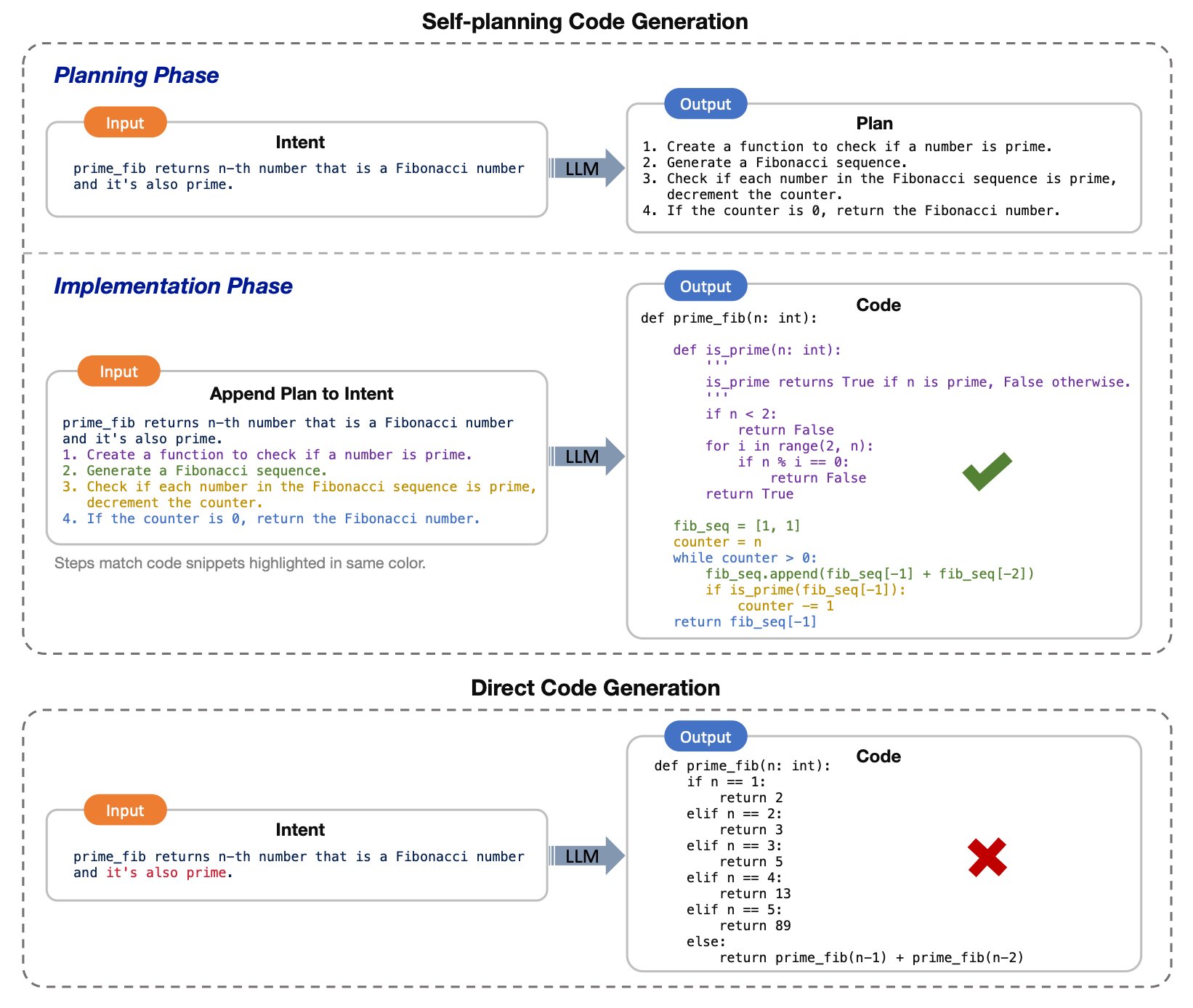
In the last few months, multiple researchers have tried to push the limits of what generative AI can do, and have discovered that large language models can perform very complex tasks if requested to articulate a step-by-step strategy to reach the solution.

And once you have that, you can start thinking about an iterative process where the large language model self-plans the code that was originally requested by the user:
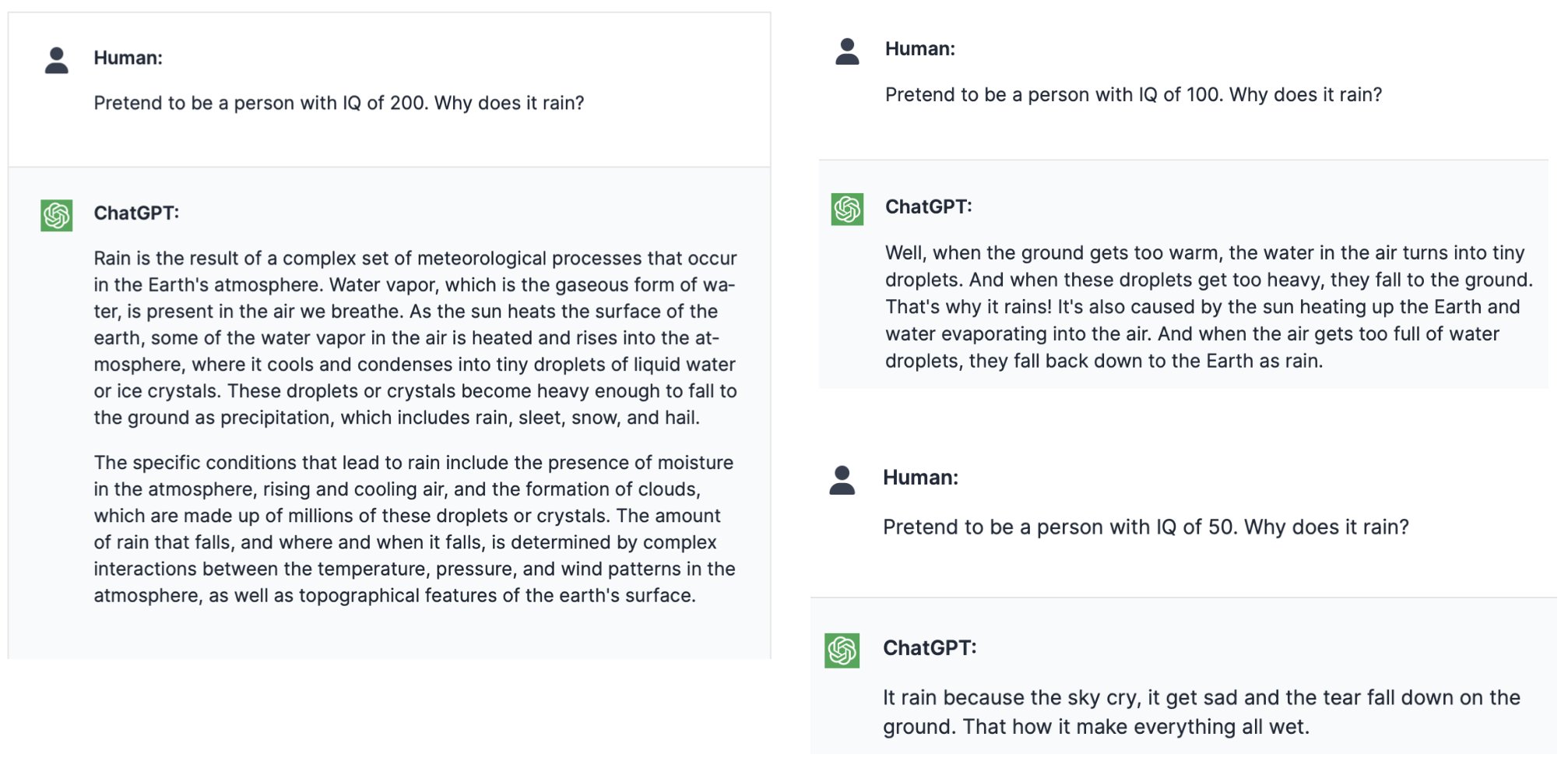
Researchers have also discovered that large language models can be significantly more articulated and precise if given the target in terms of quality.
Frederic Besse, a Senior Staff Research Engineer at DeepMind, stretched these ideas and, instead of defining the ambitions of the AI, he defined a new role for it:
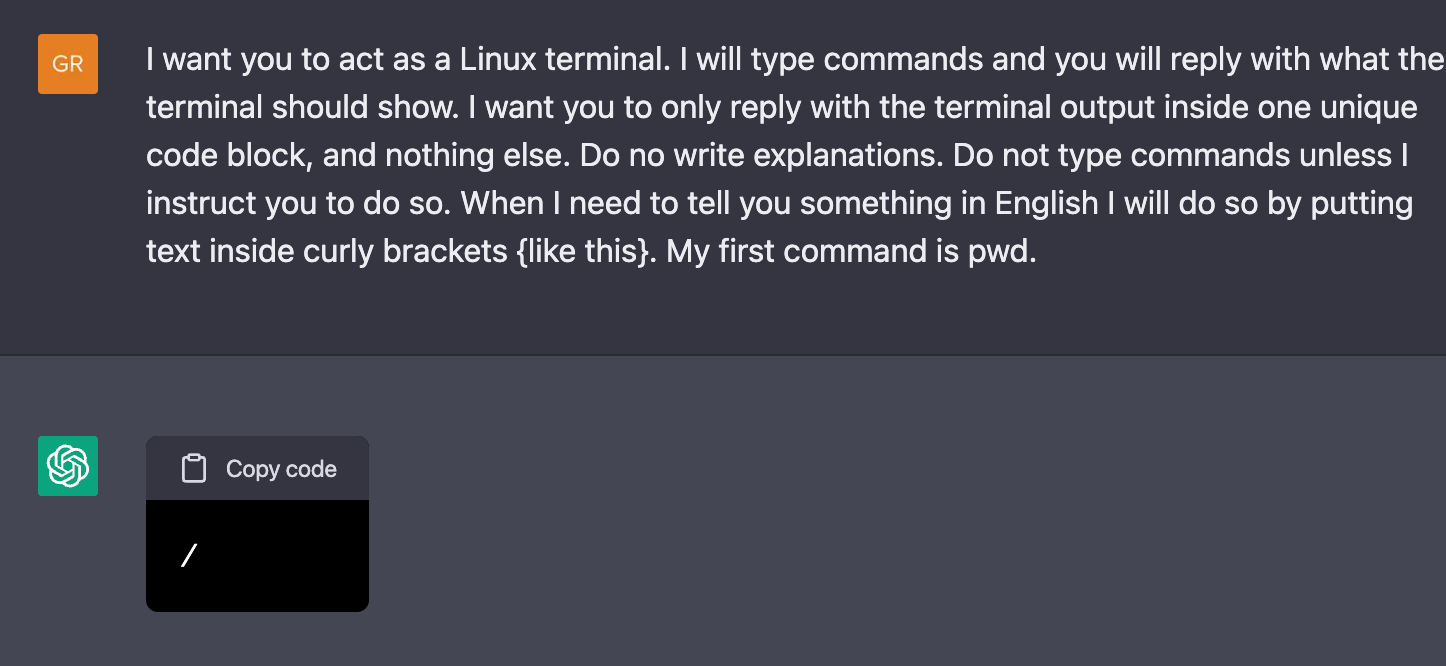
As the AI attempts to emulate anything it has learned, the AI starts to behave in the most plausible way a Linux terminal behaves, according to what it learned.
Besse manages to navigate a file system, save a text file, execute some programming code, explore the internet with the text-based browser, and create another Linux terminal inside the Linux terminal that the AI is pretending to be.
I just hope the guy was not under the effects of some drugs or he might never recover from that trippy experience.
If all of this is possible, then it’s possible to program the AI, in natural language, how to treat inputs to generate output. Which is what If all of this is possible, then it’s possible to program the AI, in natural language, how to treat inputs to generate output. Which is what Mate Marschalko managed to do when he programmed GPT-3 to behave like Siri:
Mate managed to replace Siri with GPT-3 with the following prompt, which is passed every time to GPT-3 via Siri Shortcuts:

If all of this is true, then perhaps we can even teach a large language model how to fix the bugs in a piece of software.
That’s what an anonymous AI researcher has done with his Wolverine project (be certain to watch the video full screen):
Today I used GPT-4 to make "Wolverine" – it gives your python scripts regenerative healing abilities!
Run your scripts with it and when they crash, GPT-4 edits them and explains what went wrong. Even if you have many bugs it'll repeatedly rerun until everything is fixed pic.twitter.com/gN0X7pA2M2
— BioBootloader (@bio_bootloader) March 18, 2023
This is the magic prompt he/she used:
You are part of an elite automated software fixing team. You will be given a script followed by the arguments it was provided and the stacktrace of the error it produced. Your job is to figure out what went wrong and suggest changes to the code.
Because you are part of an automated system, the format you respond in is very strict. You must provide changes in JSON format, using one of 3 actions: ‘Replace’, ‘Delete’, or ‘InsertAfter’. ‘Delete’ will remove that line from the code. ‘Replace’ will replace the existing line with the content you provide. ‘InsertAfter’ will insert the new lines you provide after the code already at the specified line number. For multi-line insertions or replacements, provide the content as a single string with ‘\n’ as the newline character. The first line in each file is given line number 1. Edits will be applied in reverse line order so that line numbers won’t be impacted by other edits.
In addition to the changes, please also provide short explanations of the what went wrong. A single explanation is required, but if you think it’s helpful, feel free to provide more explanations for groups of more complicated changes. Be careful to use proper indentation and spacing in your changes. An example response could be:
[
{“explanation”: “this is just an example, this would usually be a brief explanation of what went wrong”},
{“operation”: “InsertAfter”, “line”: 10, “content”: “x = 1\ny = 2\nz = x * y”},
{“operation”: “Delete”, “line”: 15, “content”: “”},
{“operation”: “Replace”, “line”: 18, “content”: “x += 1”},
{“operation”: “Delete”, “line”: 20, “content”: “”}
]
So, here we are entering unexplored territories where not only we can translate plain English into existing programming languages, but we can also use plain English as a new type of programming language.
Which is really like teaching a person how to do a certain job (like cooking a meal or loading the dishwasher).
So far, so mind-blowing.
But what about the things that large language models don’t know?
The data set generative AI systems are trained on have a cutoff date. Anything that has been written, said, discovered, or eliminated from the world after that cutoff date is unknown by the AI. Plus, training data sets are still incomplete at this point.
We don’t have yet a way to train AI on everything that exists in the world.
So how do you instruct a large language model to manipulate something it doesn’t know in the first place?
That’s here that things get really exciting (Don’t judge me. I find joy in the weirdest things.)
This is what I imagined just last month:
Right now, you need to do a lot of training to teach a large language model how to generate high-quality code for the task you want. In the future, expect something like this:
You: can you write me an API call in Python for service X?
Copilot: Where's the doc?
You: https:// …— Alessandro Perilli ✍️ Synthetic Work 🇺🇦 (@giano) February 8, 2023
Just two days later, researchers at Meta showed that an AI model can be trained to learn how to use software via its APIs in a completely unsupervised (it means no human is involved) way.
Not only that. The researchers have demonstrated that the AI model can figure out by itself what is the best API to call to answer a given prompt, when to call it, and what arguments to use to obtain the information necessary to compose the answer for the user.

While this is not quite like pointing the AI to the doc of a tool it has never seen to learn about it, it’s a major step in that direction.
And while we wait for this to happen, we can enjoy other mind-blowing proposals, like the one from Scale AI.
Our vision for a future tech stack is to completely replace the backend with an LLM that can both run logic and store memory. We demonstrated this with a Todo app.
— DY (@DYtweetshere) January 23, 2023
Same idea we mentioned before, very different implementation: since a large language model tries to replicate anything it has learned during training, we can ask it to pretend to be, for example, a database.
At that point, the large language model will store the data we fed it through a prompt like a database would. From there, we can ask it to pretend that we wrote a number of functions to manipulate that data, calling the corresponding API with new prompt interactions.
There are so many more wild ideas to talk about but at this point I start to feel in this way and perhaps it’s a sign we should pause here for this week.